2 способа корреляционного анализа в microsoft excel
Содержание:
- Корреляционный анализ в Excel
- Использование MS EXCEL для расчета ковариации
- Пример регрессионного анализа №2
- Что представляет собой корреляционный анализ
- Разбор результатов анализа
- Разбор результатов анализа
- Математическое определение регрессии
- Другие виды регрессии
- Корреляция и диверсификация
- Синтаксис
- Анализ коэффициентов
- Расчет коэффициента корреляции
- Изучение результатов и выводы
- Изучение результатов и выводы
Корреляционный анализ в Excel
Корреляционный анализ помогает установить, есть ли между показателями в одной или двух выборках связь. Например, между временем работы станка и стоимостью ремонта, ценой техники и продолжительностью эксплуатации, ростом и весом детей и т.д.
Если связь имеется, то влечет ли увеличение одного параметра повышение (положительная корреляция) либо уменьшение (отрицательная) другого. Корреляционный анализ помогает аналитику определиться, можно ли по величине одного показателя предсказать возможное значение другого.
Коэффициент корреляции обозначается r. Варьируется в пределах от +1 до -1. Классификация корреляционных связей для разных сфер будет отличаться. При значении коэффициента 0 линейной зависимости между выборками не существует.
Рассмотрим, как с помощью средств Excel найти коэффициент корреляции.
Для нахождения парных коэффициентов применяется функция КОРРЕЛ.
Задача: Определить, есть ли взаимосвязь между временем работы токарного станка и стоимостью его обслуживания.
Ставим курсор в любую ячейку и нажимаем кнопку fx.
- В категории «Статистические» выбираем функцию КОРРЕЛ.
- Аргумент «Массив 1» — первый диапазон значений – время работы станка: А2:А14.
- Аргумент «Массив 2» — второй диапазон значений – стоимость ремонта: В2:В14. Жмем ОК.
Чтобы определить тип связи, нужно посмотреть абсолютное число коэффициента (для каждой сферы деятельности есть своя шкала).
Для корреляционного анализа нескольких параметров (более 2) удобнее применять «Анализ данных» (надстройка «Пакет анализа»). В списке нужно выбрать корреляцию и обозначить массив. Все.
Полученные коэффициенты отобразятся в корреляционной матрице. Наподобие такой:
Использование MS EXCEL для расчета ковариации
Ковариация
близка по смыслу с дисперсией (также является мерой разброса) с тем отличием, что она определена для 2-х переменных, адисперсия — для одной. Поэтому, cov(x;x)=VAR(x).
Для вычисления ковариации в MS EXCEL (начиная с версии 2010 года) используются функции КОВАРИАЦИЯ.Г() и КОВАРИАЦИЯ.В() . В первом случае формула для вычисления аналогична вышеуказанной (окончание .Г
обозначаетГенеральная совокупность ), во втором – вместо множителя 1/n используется 1/(n-1), т.е. окончание.В обозначаетВыборка .
Примечание
: Функция КОВАР() , которая присутствует в MS EXCEL более ранних версий, аналогична функции КОВАРИАЦИЯ.Г() .
Примечание
: Функции КОРРЕЛ() и КОВАР() в английской версии представлены как CORREL и COVAR. Функции КОВАРИАЦИЯ.Г() и КОВАРИАЦИЯ.В() как COVARIANCE.P и COVARIANCE.S.
Дополнительные формулы для расчета ковариации
= СУММПРОИЗВ(B28:B88-СРЗНАЧ(B28:B88);(D28:D88-СРЗНАЧ(D28:D88)))/СЧЁТ(D28:D88)
= СУММПРОИЗВ(B28:B88-СРЗНАЧ(B28:B88);(D28:D88))/СЧЁТ(D28:D88)
= СУММПРОИЗВ(B28:B88;D28:D88)/СЧЁТ(D28:D88)-СРЗНАЧ(B28:B88)*СРЗНАЧ(D28:D88)
Эти формулы используют свойство ковариации
Если переменные x
иy независимые, то их ковариация равна 0. Если переменные не являются независимыми, то дисперсия их суммы равна:
VAR(x+y)= VAR(x)+ VAR(y)+2COV(x;y)
А дисперсия
их разности равна
VAR(x-y)= VAR(x)+ VAR(y)-2COV(x;y)
Пример регрессионного анализа №2
Второй случай, в котором можно проводить регрессионный анализ – это необходимость найти максимальную модель распределения расходов на разные виды рекламы для того, чтобы получить самую большую прибыль. И такую маркетинговую задачу вполне может решить обычный Excel, кто бы мог подумать?
Предположим, максимальный бюджет на рекламу, который может быть потрачен организацией – 170000 рублей. Это ограничение невозможно предусмотреть стандартным средством, описанным выше. Здесь нужно использовать совсем другую надстройку, которая называется «Поиск решения». Есть ее возможность найти в том же разделе, что и описываемую нами. И аналогично пакету анализа, нам необходимо включить эту надстройку в том же самом меню.
Что же собой являет инструмент «Поиск решения»? Это надстройка, позволяющая найти оптимальный способ решения определенной задачи. Она имеет два основных параметра: целевая функция и ограничения. Таким образом, пользователь может находить оптимальную сумму затрат для рекламу в определенных условиях. Это одно из главных преимуществ данного инструмента.
Точно также, как в случае с пакетом анализа, инструмент поиска решения требует наличия математической модели. В качестве неё и выступает целевая функция. В нашем случае она следующая: Y= 2102438,6 + 6,4004 X1 — 54,068 X2 > max. В качестве используемых ограничений используется следующее выражение: X1 + X2 <= 170000, X1>= 0, X2 >=0.
После применения инструмента «Поиск решения» оказывается, что при заданных параметрах и ограничениях оптимально тратить деньги на рекламу по телевидению, поскольку это способно обеспечить максимальную прибыль. Как же пользоваться этим инструментом на практике? Для этого нужно выполнить следующие простые действия.
- Для начала нажать «Параметры Excel», после чего отправиться в категорию «Надстройки».
- После этого в поле «Управление» найти «Надстройки Excel» и кликнуть по «Перейти».
- После этого в списке надстроек активировать «Поиск решения».
После нажатия клавиши ОК надстройка успешно активирована. Далее достаточно просто нажимать на соответствующую кнопку на вкладке «Данные» в той же группе, что и пакет анализа и задать подходящие параметры. После этого программа все сделает самостоятельно. Таким образом, использование регрессии в Excel – очень простая штука. Значительно легче, чем может показаться на первый взгляд, поскольку большую часть действий выполняет программа. Достаточно просто вбить правильные настройки, и дальше можно расслабиться. И да, нужно еще интерпретировать результаты правильно. Но это не проблема. Успехов.
Что представляет собой корреляционный анализ
Простыми словами, корреляция – это связь между двумя явлениями. В свою очередь, под корреляционным анализом подразумевают выявление этой связи. Очень частое утверждение гласит, что корреляция – это зависимость между разными объектами, но на деле это неточное определение. Ведь существует множество изображений, которые показывают связь между явлениями, которые никак не могут быть зависимы друг от друга или одного третьего фактора, который влияет на них.
Величина, определяющая степень выраженности взаимосвязи, называется коэффициентом корреляции. Это единственная величина, которая рассчитывается корреляционным анализом по сравнению с регрессионным. Возможные вариации коэффициента корреляции могут быть в пределах от -1 до 1. Если это число положительное, взаимосвязь между динамикой изменения значений прямая. Если же отрицательное, то увеличение числа 1 приводит к аналогичному уменьшению числа 2. Если число меньше единицы по модулю, то корреляция неполная. Например, увеличение числа 1 на единицу приводит к увеличению числа 2 на 0,5. В таком случае коэффициент корреляции составляет 0,5. Если же коэффициент корреляции составляет 0, то взаимосвязи между двумя переменными нет.
Интересный факт: корреляции делятся на истинные и ложные. То есть, иногда то, что графики идут в одинаковом направлении, может быть чистой случайностью, а не закономерным следствием воздействия одной переменной на другую или влияния общего фактора на обе переменные. В узких кругах довольно популярны картинки, где коррелируют между собой абсолютно не связанные явления. Вот некоторые примеры:
- Количество человек, которые стали утопленниками в бассейнах, четко коррелирует с количеством фильмов, в которых Николас Кейдж был актером.
- Количество съеденной моцареллы и количество человек, которые получили докторскую степень, также коррелирует на протяжении 2000-2009 годов. Наверно, действительно, моцарелла как-то влияет на мозг и стимулирует желание совершать научные открытия.
- Почти во всех случаях средний возраст женщин, которые получили статус «Мисс Америка» коррелирует с количеством людей, которые погибли от нахождения в горячем паре.
- Число людей, которое погибло в результате дорожно-транспортного происшествия, четко коррелирует с количеством сметаны, которое съедают люди.
- Мало кто знает, что чем больше курятины человек ест, тем больше сырой нефти импортируется в мире. Правда, это тоже пример ложной корреляции. Кстати, импорт сырой нефти родом из Норвегии тесно связано с количеством людей, которые погибли в результате столкновения автомобиля с поездом. Причем в этом случае корреляция почти 100 процентов.
- А еще маргарин негативно влияет на статистику разводов. Чем больше людей, которые проживали в штате Мэн, потребляли маргарина, тем выше была частота разводов. Правда, здесь еще может быть рациональное зерно. Ведь частота потребления маргарина имеет обратную корреляцию с экономическим положением в семье. В свою очередь, плохое экономическое положение в семье имеет непосредственную связь с количеством разводов. И это уже доказано научно. Так что кто знает, может, эта корреляция и не является такой ложной. Правда, никто этого не перепроверял.
- Количество денег, которое правительство США тратит на развитие науки, космоса и технологий, имеет тесную связь с количеством самоубийств, проведенных в форме повешения или удушения.
Поэтому несмотря на то, что корреляция является эффективным статистическим инструментом, нужно учиться отфильтровывать истинные взаимосвязи между явлениями и ложные. Иначе исследование может получить такие интересные результаты. А теперь переходим непосредственно к тому, как проводить корреляционный анализ в Excel.
Разбор результатов анализа
Результаты регрессионного анализа выводятся в виде таблицы в том месте, которое указано в настройках.

Одним из основных показателей является R-квадрат. В нем указывается качество модели. В нашем случае данный коэффициент равен 0,705 или около 70,5%. Это приемлемый уровень качества. Зависимость менее 0,5 является плохой.
Ещё один важный показатель расположен в ячейке на пересечении строки «Y-пересечение» и столбца «Коэффициенты». Тут указывается какое значение будет у Y, а в нашем случае, это количество покупателей, при всех остальных факторах равных нулю. В этой таблице данное значение равно 58,04.
Значение на пересечении граф «Переменная X1» и «Коэффициенты» показывает уровень зависимости Y от X. В нашем случае — это уровень зависимости количества клиентов магазина от температуры. Коэффициент 1,31 считается довольно высоким показателем влияния.
Как видим, с помощью программы Microsoft Excel довольно просто составить таблицу регрессионного анализа. Но, работать с полученными на выходе данными, и понимать их суть, сможет только подготовленный человек.
Мы рады, что смогли помочь Вам в решении проблемы.
Помогла ли вам эта статья?
Метод линейной регрессии позволяет нам описывать прямую линию, максимально соответствующую ряду упорядоченных пар (x, y). Уравнение для прямой линии, известное как линейное уравнение, представлено ниже:
ŷ — ожидаемое значение у при заданном значении х,
x — независимая переменная,
a — отрезок на оси y для прямой линии,
b — наклон прямой линии.
На рисунке ниже это понятие представлено графически:
На рисунке выше показана линия, описанная уравнением ŷ =2+0.5х. Отрезок на оси у — это точка пересечения линией оси у; в нашем случае а = 2. Наклон линии, b, отношение подъема линии к длине линии, имеет значение 0.5. Положительный наклон означает, что линия поднимается слева направо. Если b = 0, линия горизонтальна, а это значит, что между зависимой и независимой переменными нет никакой связи. Иными словами, изменение значения x не влияет на значение y.
Часто путают ŷ и у. На графике показаны 6 упорядоченных пар точек и линия, в соответствии с данным уравнением
На этом рисунке показана точка, соответствующая упорядоченной паре х = 2 и у = 4
Обратите внимание, что ожидаемое значение у в соответствии с линией при х
= 2 является ŷ. Мы можем подтвердить это с помощью следующего уравнения:
ŷ = 2 + 0.5х =2 +0.5(2) =3.
Значение у представляет собой фактическую точку, а значение ŷ — это ожидаемое значение у с использованием линейного уравнения при заданном значении х.
Следующий шаг — определить линейное уравнение, максимально соответствующее набору упорядоченных пар, об этом мы говорили в предыдущей статье, где определяли вид уравнения по методу наименьших квадратов.
Разбор результатов анализа
Результаты регрессионного анализа выводятся в виде таблицы в том месте, которое указано в настройках.

Одним из основных показателей является R-квадрат. В нем указывается качество модели. В нашем случае данный коэффициент равен 0,705 или около 70,5%. Это приемлемый уровень качества. Зависимость менее 0,5 является плохой.
Ещё один важный показатель расположен в ячейке на пересечении строки «Y-пересечение» и столбца «Коэффициенты». Тут указывается какое значение будет у Y, а в нашем случае, это количество покупателей, при всех остальных факторах равных нулю. В этой таблице данное значение равно 58,04.
Значение на пересечении граф «Переменная X1» и «Коэффициенты» показывает уровень зависимости Y от X. В нашем случае — это уровень зависимости количества клиентов магазина от температуры. Коэффициент 1,31 считается довольно высоким показателем влияния.
Как видим, с помощью программы Microsoft Excel довольно просто составить таблицу регрессионного анализа. Но, работать с полученными на выходе данными, и понимать их суть, сможет только подготовленный человек.
Мы рады, что смогли помочь Вам в решении проблемы.
Помогла ли вам эта статья?
Да Нет
Регрессионный и корреляционный анализ – статистические методы исследования. Это наиболее распространенные способы показать зависимость какого-либо параметра от одной или нескольких независимых переменных.
Ниже на конкретных практических примерах рассмотрим эти два очень популярные в среде экономистов анализа. А также приведем пример получения результатов при их объединении.
Математическое определение регрессии
Строго регрессионную зависимость можно определить следующим образом. Пусть , — случайные величины с заданным совместным распределением вероятностей. Если для каждого набора значений определено условное математическое ожидание
то функция называется регрессией
величины Y по величинам , а её график — линией регрессии
по , или уравнением регрессии
.
Зависимость от проявляется в изменении средних значений Y при изменении . Хотя при каждом фиксированном наборе значений величина остаётся случайной величиной с определённым рассеянием.
Для выяснения вопроса, насколько точно регрессионный анализ оценивает изменение Y при изменении , используется средняя величина дисперсии Y при разных наборах значений (фактически речь идет о мере рассеяния зависимой переменной вокруг линии регрессии).
Другие виды регрессии
В примере, который представлен выше, используется только две переменных. Такая ситуация является скорее редкостью. Для расчета нескольких или разных показателей используют иные методы регрессии.
Множественная
Техника применяется в случае, когда параметров Х больше одного. Чтобы корректно рассчитать характеристики можно использовать дополнительные инструменты: заданный тренд, коэффициент детерминации, проверка гипотез и иные. Выполнить расчеты может только подготовленный специалист.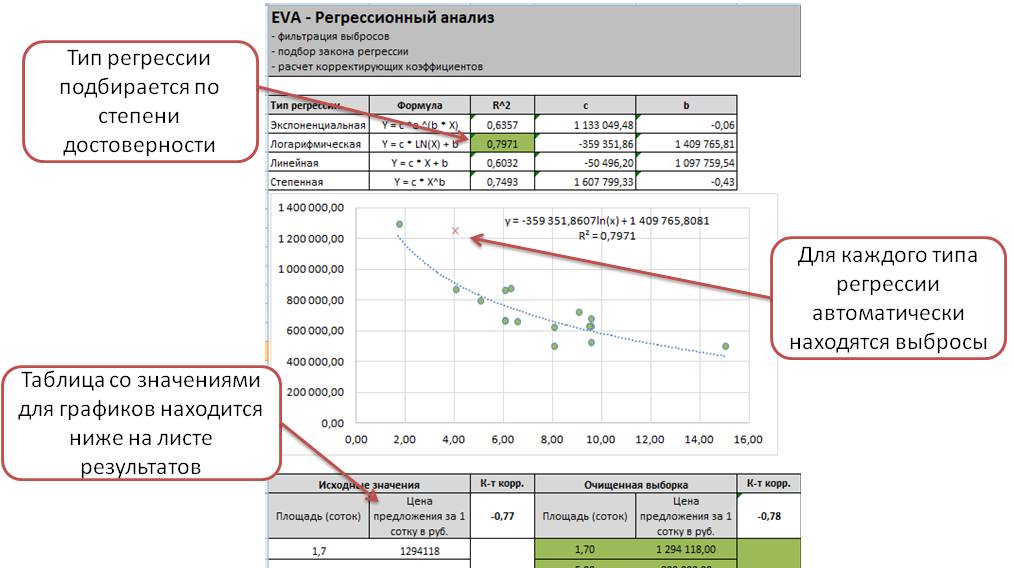
Степенная
Для этой модели формула расчета выглядит так: y = a*x˄b. Выбросы для данного метода вычисляются автоматически. Используется, если уровень достоверности техники выше остальных – графа R˄2.
Нелинейная
Для нелинейной методики важно рассчитать коэффициент корреляции. Характеристика указывает на наличие взаимосвязи различных показателей
Как правило, если параметр близок к единице, то взаимодействие есть, а анализ достаточно точный.
Дополнительным элементом является относительная ошибка. Характеристика должна находиться в пределах от 8% до 10% – значит, что расчеты точные и результаты можно использовать дальше.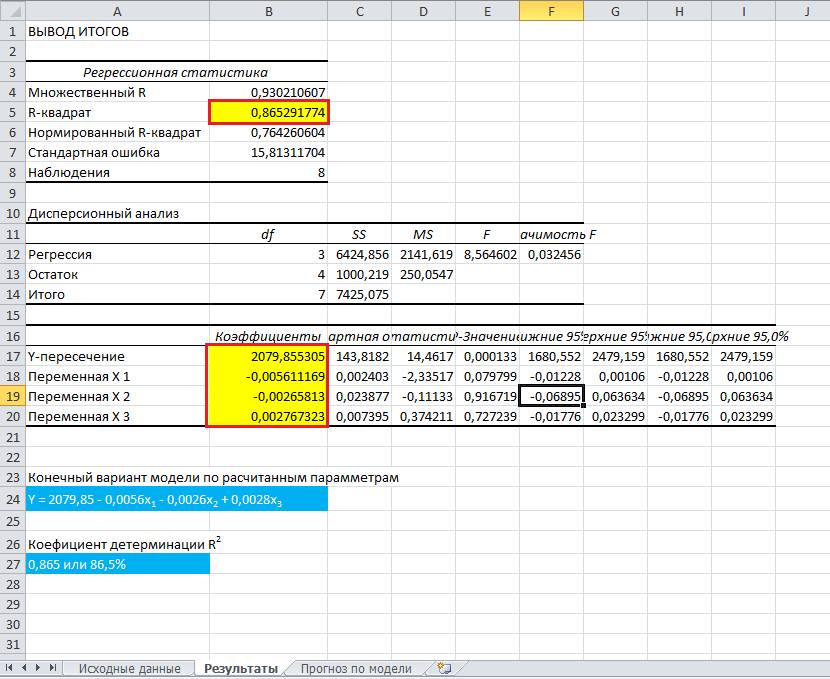
Кроме основных типов регрессионного анализа в Excel используют различные сочетания техник. К примеру, для исследования данных в банковской сфере, колебаний демографических показателей и других
Чтобы корректно пользоваться результатами, важно детально изучить механизм работы подобного исследования. Чаще всего обращаются к специалистам соответствующего профиля
Корреляция и диверсификация
Как знания о корреляции активов могут помочь лучше вкладывать деньги? Думаю, вы все хорошо знакомы с золотым правилом инвестора — не клади все яйца в одну корзину. Речь, естественно, идёт о диверсификации инвестиционных активов в портфеле. Корреляция и диверсификация неразрывно связаны, что понятно даже из названия — английское diversify означает «разнообразить», а как коэффициент корреляции как раз показывает схожесть или различие двух явлений.
Другими словами, инвестировать в финансовые инструменты с высокой корреляцией не очень хорошо. Почему? Все просто — похожие активы плохо диверсифицируются. Вот пример портфеля двух активов с корреляцией +1:
Как видите, график портфеля во всех деталях повторяет графики каждого из активов — рост и падение обоих активов синхронны. Диверсификация в теории должна снижать инвестиционные риски за счёт того, что убытки одного актива перекрываются за счёт прибыли другого, но здесь этого не происходит совершенно. Все показатели просто усредняются:
Портфель даёт небольшой выигрыш в снижении рисков — но только по сравнению с более доходным Активом 1. А так, никаких преимуществ по сути нет, нам лучше просто вложить все деньги в Актив 1 и не париться.
А вот пример портфеля двух активов с корреляцией близкой к 0:
Где-то графики следуют друг за другом, где-то в противоположных направлениях, какой-либо однозначной связи не наблюдается. И вот здесь диверсификация уже работает:
Мы видим заметное снижение СКО, а значит портфель будет менее волатильным и более стабильно расти. Также видим небольшое снижение максимальной просадки, особенно если сравнивать с Активом 1. Инвестиционные инструменты без корреляции достаточно часто встречаются и из них имеет смысл составлять портфель.
Впрочем, это не предел. Наиболее эффективный инвестиционный портфель можно получить, используя активы с корреляцией -1:
Уже знакомое вам «зеркало» позволяет довести показатели риска портфеля до минимальных:
Несмотря на то, что каждый из активов обладает определенным риском, портфель получился фактически безрисковым. Какая-то магия, не правда ли? Очень жаль, но на практике такого не бывает, иначе инвестирование было бы слишком лёгким занятием.
Синтаксис
-
Известные_значения_y. Обязательный аргумент. Множество значений y, которые уже известны для соотношения y = mx + b.
-
Если массив известные_значения_y имеет один столбец, то каждый столбец массива известные_значения_x интерпретируется как отдельная переменная.
-
Если массив известные_значения_y имеет одну строку, то каждая строка массива известные_значения_x интерпретируется как отдельная переменная.
-
-
Известные_значения_x. Необязательный аргумент. Множество значений x, которые уже известны для соотношения y = mx + b.
-
Массив известные_значения_x может содержать одно или несколько множеств переменных. Если используется только одна переменная, то массивы известные_значения_y и известные_значения_x могут иметь любую форму — при условии, что они имеют одинаковую размерность. Если используется более одной переменной, то известные_значения_y должны быть вектором (т. е. интервалом высотой в одну строку или шириной в один столбец).
-
Если массив известные_значения_x опущен, то предполагается, что это массив {1;2;3;…}, имеющий такой же размер, что и массив известные_значения_y.
-
-
Конст. Необязательный аргумент. Логическое значение, которое указывает, требуется ли, чтобы константа b была равна 0.
-
Если аргумент конст имеет значение ИСТИНА или опущен, то константа b вычисляется обычным образом.
-
Если аргумент конст имеет значение ЛОЖЬ, то значение b полагается равным 0 и значения m подбираются таким образом, чтобы выполнялось соотношение y = mx.
-
-
Статистика. Необязательный аргумент. Логическое значение, которое указывает, требуется ли вернуть дополнительную регрессионную статистику.
-
Если статистика имеет true, то LINEST возвращает дополнительную регрессию; в результате возвращается массив {mn;mn-1,…,m1;b;sen,sen-1,…,se1;seb;r2;sey; F,df;ssreg,ssresid}.
-
Если аргумент статистика имеет значение ЛОЖЬ или опущен, функция ЛИНЕЙН возвращает только коэффициенты m и постоянную b.
Дополнительная регрессионная статистика.
-
|
Величина |
Описание |
|---|---|
|
se1,se2,…,sen |
Стандартные значения ошибок для коэффициентов m1,m2,…,mn. |
|
seb |
Стандартное значение ошибки для постоянной b (seb = #Н/Д, если аргумент конст имеет значение ЛОЖЬ). |
|
r2 |
Коэффициент определения. Сравнивает предполагаемые и фактические значения y и диапазоны значений от 0 до 1. Если значение 1, то в выборке будет отличная корреляция— разница между предполагаемым значением y и фактическим значением y не существует. С другой стороны, если коэффициент определения — 0, уравнение регрессии не помогает предсказать значение y. Сведения о том, каквычисляется 2, см. в разделе «Замечания» далее в этой теме. |
|
sey |
Стандартная ошибка для оценки y. |
|
F |
F-статистика или F-наблюдаемое значение. F-статистика используется для определения того, является ли случайной наблюдаемая взаимосвязь между зависимой и независимой переменными. |
|
df |
Степени свободы. Степени свободы используются для нахождения F-критических значений в статистической таблице. Для определения уровня надежности модели необходимо сравнить значения в таблице с F-статистикой, возвращаемой функцией ЛИНЕЙН. Дополнительные сведения о вычислении величины df см. ниже в разделе «Замечания». Далее в примере 4 показано использование величин F и df. |
|
ssreg |
Регрессионная сумма квадратов. |
|
ssresid |
Остаточная сумма квадратов. Дополнительные сведения о расчете величин ssreg и ssresid см. в подразделе «Замечания» в конце данного раздела. |
На приведенном ниже рисунке показано, в каком порядке возвращается дополнительная регрессионная статистика.
Анализ коэффициентов
Число 64,1428 показывает, каким будет значение Y, если все переменные xi в рассматриваемой нами модели обнулятся. Иными словами можно утверждать, что на значение анализируемого параметра оказывают влияние и другие факторы, не описанные в конкретной модели.
Следующий коэффициент -0,16285, расположенный в ячейке B18, показывает весомость влияния переменной Х на Y. Это значит, что среднемесячная зарплата сотрудников в пределах рассматриваемой модели влияет на число уволившихся с весом -0,16285, т. е. степень ее влияния совсем небольшая. Знак «-» указывает на то, что коэффициент имеет отрицательное значение. Это очевидно, так как всем известно, что чем больше зарплата на предприятии, тем меньше людей выражают желание расторгнуть трудовой договор или увольняется.
Расчет коэффициента корреляции
Теперь давайте попробуем посчитать коэффициент корреляции на конкретном примере. Имеем таблицу, в которой помесячно расписана в отдельных колонках затрата на рекламу и величина продаж. Нам предстоит выяснить степень зависимости количества продаж от суммы денежных средств, которая была потрачена на рекламу.
Способ 1: определение корреляции через Мастер функций
Одним из способов, с помощью которого можно провести корреляционный анализ, является использование функции КОРРЕЛ. Сама функция имеет общий вид КОРРЕЛ(массив1;массив2).
- Выделяем ячейку, в которой должен выводиться результат расчета. Кликаем по кнопке «Вставить функцию», которая размещается слева от строки формул.
В списке, который представлен в окне Мастера функций, ищем и выделяем функцию КОРРЕЛ. Жмем на кнопку «OK».
Открывается окно аргументов функции. В поле «Массив1» вводим координаты диапазона ячеек одного из значений, зависимость которого следует определить. В нашем случае это будут значения в колонке «Величина продаж». Для того, чтобы внести адрес массива в поле, просто выделяем все ячейки с данными в вышеуказанном столбце.
В поле «Массив2» нужно внести координаты второго столбца. У нас это затраты на рекламу. Точно так же, как и в предыдущем случае, заносим данные в поле.
Жмем на кнопку «OK».
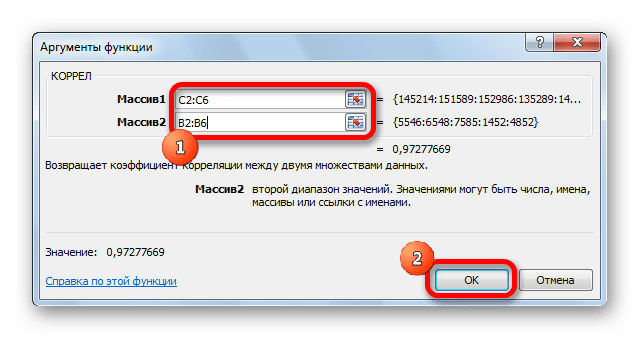
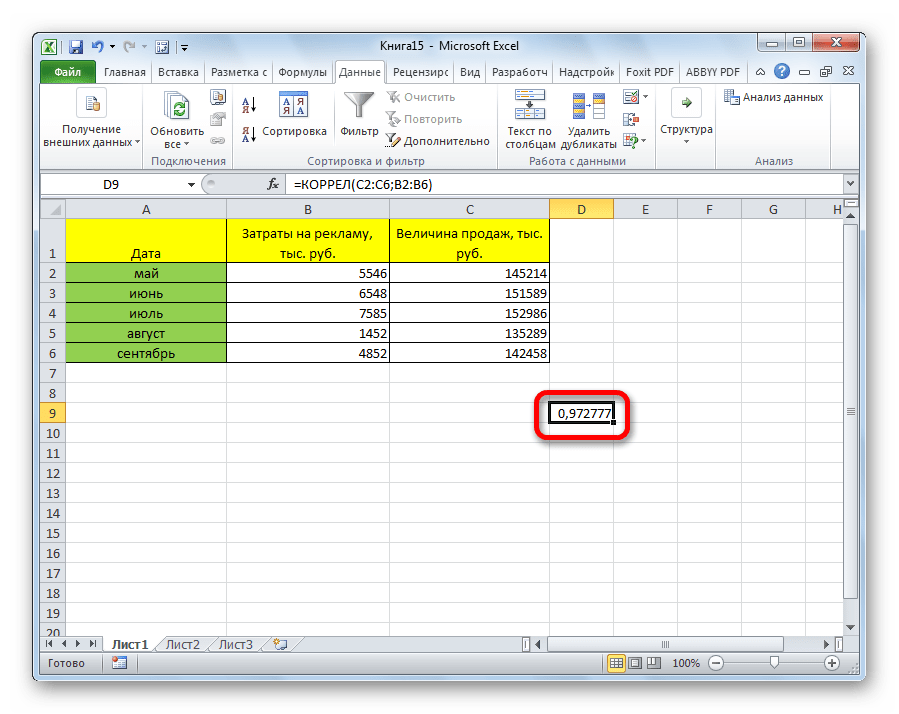
Как видим, коэффициент корреляции в виде числа появляется в заранее выбранной нами ячейке. В данном случае он равен 0,97, что является очень высоким признаком зависимости одной величины от другой.
Способ 2: вычисление корреляции с помощью пакета анализа
Кроме того, корреляцию можно вычислить с помощью одного из инструментов, который представлен в пакете анализа. Но прежде нам нужно этот инструмент активировать.
- Переходим во вкладку «Файл».
В открывшемся окне перемещаемся в раздел «Параметры».
Далее переходим в пункт «Надстройки».
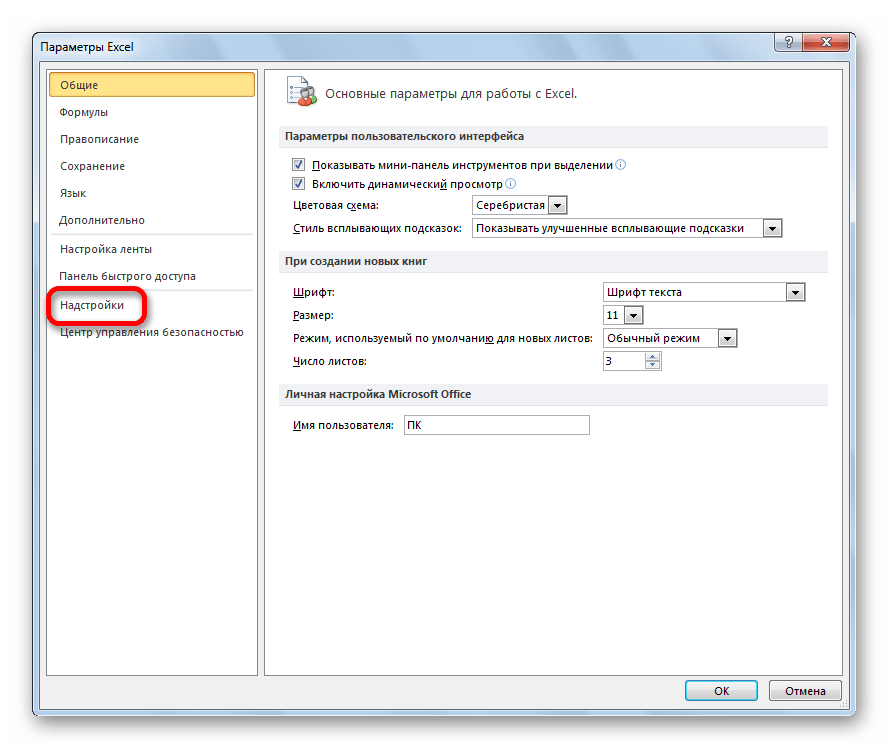
В нижней части следующего окна в разделе «Управление» переставляем переключатель в позицию «Надстройки Excel», если он находится в другом положении. Жмем на кнопку «OK».
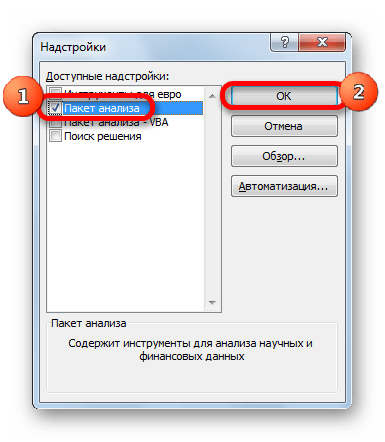
В окне надстроек устанавливаем галочку около пункта «Пакет анализа». Жмем на кнопку «OK».
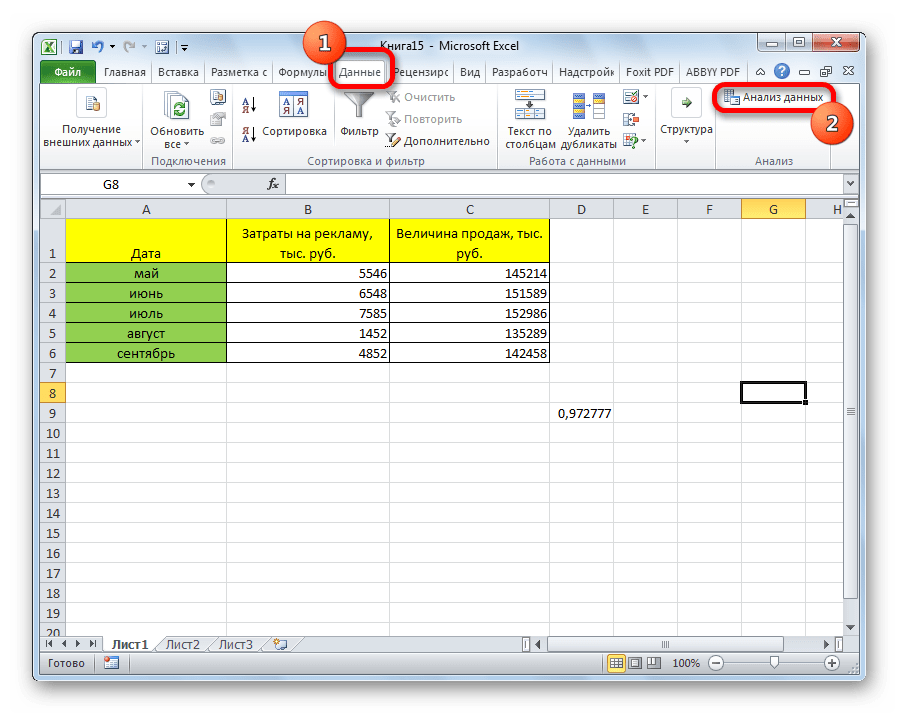
После этого пакет анализа активирован. Переходим во вкладку «Данные». Как видим, тут на ленте появляется новый блок инструментов – «Анализ». Жмем на кнопку «Анализ данных», которая расположена в нем.
Открывается список с различными вариантами анализа данных. Выбираем пункт «Корреляция». Кликаем по кнопке «OK».
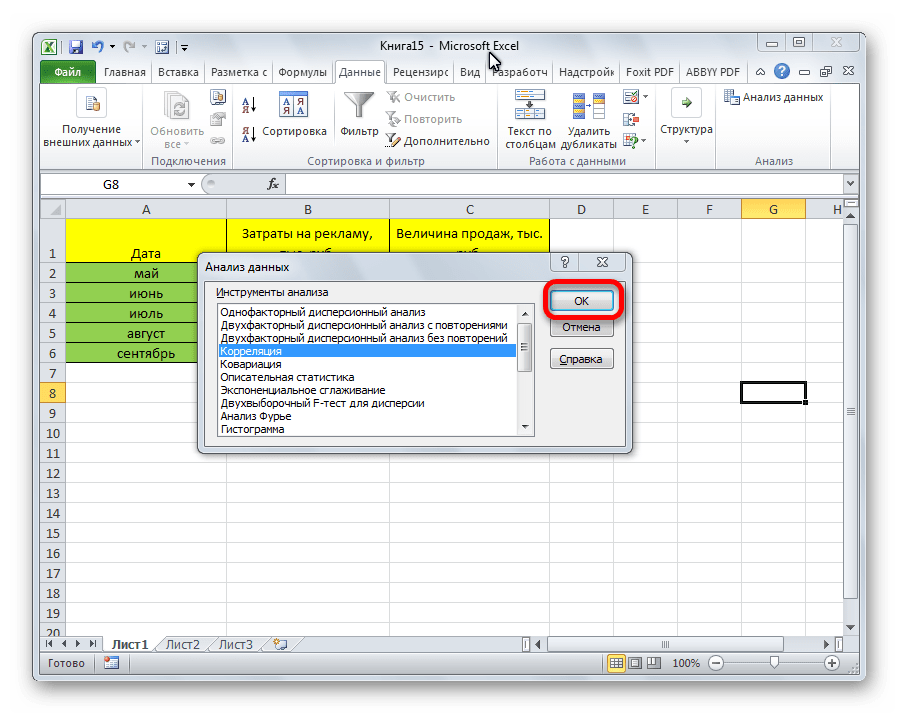
Открывается окно с параметрами корреляционного анализа. В отличие от предыдущего способа, в поле «Входной интервал» мы вводим интервал не каждого столбца отдельно, а всех столбцов, которые участвуют в анализе. В нашем случае это данные в столбцах «Затраты на рекламу» и «Величина продаж».
Параметр «Группирование» оставляем без изменений – «По столбцам», так как у нас группы данных разбиты именно на два столбца. Если бы они были разбиты построчно, то тогда следовало бы переставить переключатель в позицию «По строкам».
В параметрах вывода по умолчанию установлен пункт «Новый рабочий лист», то есть, данные будут выводиться на другом листе. Можно изменить место, переставив переключатель. Это может быть текущий лист (тогда вы должны будете указать координаты ячеек вывода информации) или новая рабочая книга (файл).
Когда все настройки установлены, жмем на кнопку «OK».
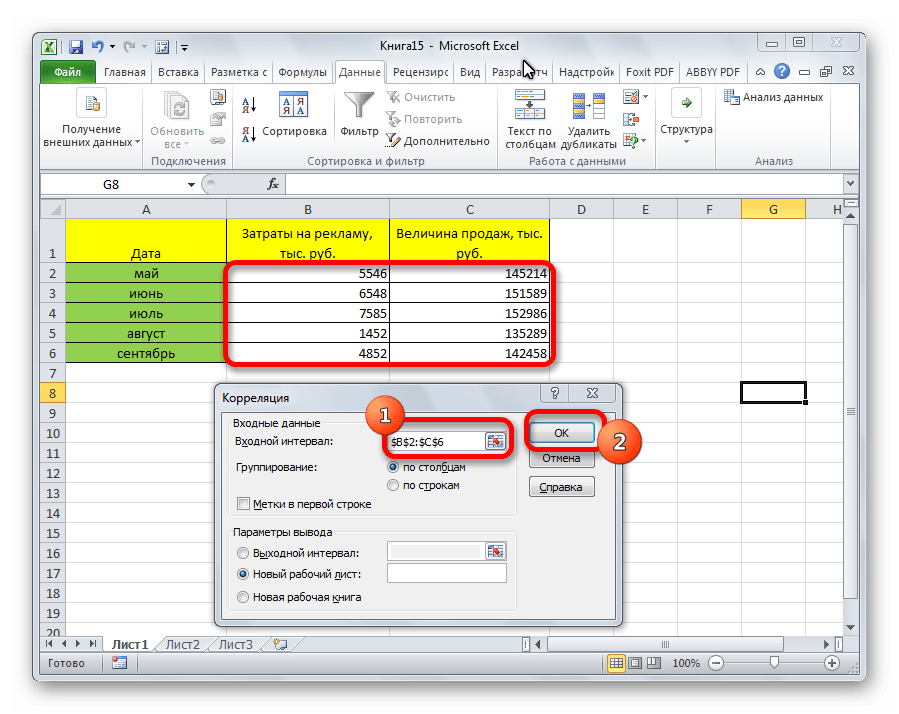
Так как место вывода результатов анализа было оставлено по умолчанию, мы перемещаемся на новый лист. Как видим, тут указан коэффициент корреляции. Естественно, он тот же, что и при использовании первого способа – 0,97. Это объясняется тем, что оба варианта выполняют одни и те же вычисления, просто произвести их можно разными способами.
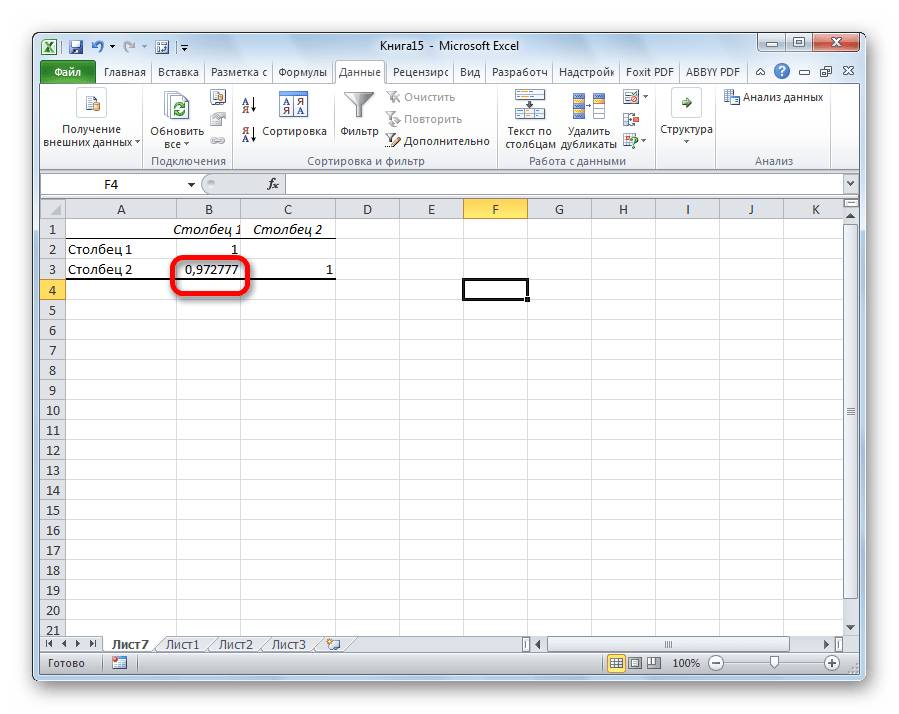
Как видим, приложение Эксель предлагает сразу два способа корреляционного анализа. Результат вычислений, если вы все сделаете правильно, будет полностью идентичным. Но, каждый пользователь может выбрать более удобный для него вариант осуществления расчета.
Опишите, что у вас не получилось.
Наши специалисты постараются ответить максимально быстро.
Изучение результатов и выводы
«Собираем» из округленных данных, представленных выше на листе табличного процессора Excel, уравнение регрессии:
СП = 0,103*СОФ + 0,541*VO — 0,031*VK +0,405*VD +0,691*VZP — 265,844.
В более привычном математическом виде его можно записать, как:
y = 0,103*x1 + 0,541*x2 — 0,031*x3 +0,405*x4 +0,691*x5 — 265,844
Данные для АО «MMM» представлены в таблице:
Подставив их в уравнение регрессии, получают цифру в 64,72 млн американских долларов. Это значит, что акции АО «MMM» не стоит приобретать, так как их стоимость в 70 млн американских долларов достаточно завышена.
Как видим, использование табличного процессора «Эксель» и уравнения регрессии позволило принять обоснованное решение относительно целесообразности вполне конкретной сделки.
Теперь вы знаете, что такое регрессия. Примеры в Excel, рассмотренные выше, помогут вам в решение практических задач из области эконометрики.
Регрессионный анализ
Регрессио́нный
(линейный
) анализ
— статистический метод исследования влияния одной или нескольких независимых переменных на зависимую переменную . Независимые переменные иначе называют регрессорами или предикторами, а зависимые переменные — критериальными. Терминология зависимых
и независимых
переменных отражает лишь математическую зависимость переменных (см. Ложная корреляция
), а не причинно-следственные отношения.
Изучение результатов и выводы
«Собираем» из округленных данных, представленных выше на листе табличного процессора Excel, уравнение регрессии:
СП = 0,103*СОФ + 0,541*VO – 0,031*VK +0,405*VD +0,691*VZP – 265,844.
В более привычном математическом виде его можно записать, как:
y = 0,103*x1 + 0,541*x2 – 0,031*x3 +0,405*x4 +0,691*x5 – 265,844
Данные для АО «MMM» представлены в таблице:
Подставив их в уравнение регрессии, получают цифру в 64,72 млн американских долларов. Это значит, что акции АО «MMM» не стоит приобретать, так как их стоимость в 70 млн американских долларов достаточно завышена.
Как видим, использование табличного процессора «Эксель» и уравнения регрессии позволило принять обоснованное решение относительно целесообразности вполне конкретной сделки.
Теперь вы знаете, что такое регрессия. Примеры в Excel, рассмотренные выше, помогут вам в решение практических задач из области эконометрики.
Регрессионный анализ является одним из самых востребованных методов статистического исследования. С его помощью можно установить степень влияния независимых величин на зависимую переменную. В функционале Microsoft Excel имеются инструменты, предназначенные для проведения подобного вида анализа. Давайте разберем, что они собой представляют и как ими пользоваться.
Но, для того, чтобы использовать функцию, позволяющую провести регрессионный анализ, прежде всего, нужно активировать Пакет анализа. Только тогда необходимые для этой процедуры инструменты появятся на ленте Эксель.


Теперь, когда мы перейдем во вкладку «Данные»
, на ленте в блоке инструментов «Анализ»
мы увидим новую кнопку – «Анализ данных»
.