Как изменить кодировку текстового файла на utf-8 или windows 1251
Содержание:
- Методы раскодировки
- ASCII и современные кодировки
- Два метода, как поменять шифровку в Word
- Откуда берутся ошибки?
- Как в Windows 10 убрать кракозябры вместо русских букв, 2 способа исправления
- Юникод
- Кодирование и декодирование
- Если кодировка не отображается
- Когда начинает применяться измененная кадастровая стоимость?
- Лучшие сайты
- Положительные стороны раскодировки
- Вероятность развития осложнений после кодирования
- Исправляем отображение русских букв в Windows 10
- Способ 1: 2cyr
Методы раскодировки
Методики раскодирования будут зависеть от кода, который применяется на практике:
- гипноз. Врач вводит пациента в состояние гипноза и дает нужные установки;
- нейтрализация. Врачу необходимо обезвредить дисульфирам, если он вводился в мышечную ткань пациента;
- удаление имплантата. Иногда применяется в срочном порядке, если, к примеру, пациент выпил алкоголь, и у него случилось отравление.
От эспераль
Эспераль представляет собой тот же дисульфирам – это препарат, который выпускается в виде таблеток или геля, организм становится восприимчивым к продуктам этанола. Даже маленькая доза может повлечь острое отравление и необходимость во врачебной помощи. Таким пациентам нельзя употреблять забродившие ягоды, настойки валерианы, конфеты с ликером. Врачи в таких случаях вводят пациентам антидот.
От дисульфирама
К сожалению, нейтрализаторов от дисульфирама нет в чистом виде, необходимо извлечение капсулы с препаратом. Народные методы и другие альтернативные средства в данном случае не работают. Извлекать препарат в домашних условиях крайне не рекомендуется – такая процедура может привести к сепсису, кровоизлияниям и к смерти пациента. Необходимо обращение за медицинской помощью.
От гипноза
В данном случае самостоятельно избавиться от гипнотических установок нельзя. Провести раскодирование может только квалифицированный специалист. Другие методы не работают, так как провести сеанс гипноза с обратными установками самостоятельно не получится.
ASCII и современные кодировки
ASCII (American standard code for information interchange) – название кодировки, разработанной и стандартизированной в США в 1963 г. Представляет собой таблицу, в которой распространенным печатным и непечатным символам сопоставлены числовые коды. В частности, она включает символы латиницы, цифр, знаков препинания.
Несмотря на существование национальных вариантов, ASCII прочно ассоциируется с символами латинского алфавита. Таким образом, символами, не входящими в ASCII, можно считать, к примеру, буквы русского алфавита или корейского хангыля.
Сегодня повсеместно распространено использование юникода – другого стандарта кодирования символов, включающего знаки большинства письменных языков мира.
Современные Windows на основе ядра NT (включая Windows 11) «под капотом» используют реализацию юникода UTF-16, однако приложения для данной ОС могут использовать и UTF-8.
Более того, Microsoft рекомендует разработчикам использовать именно ее из соображений совместимости. UTF-8 применяется по умолчанию в большинстве Unix-подобных ОС и крайне популярна в интернете. В отличие от UTF-16, UTF-8 совместима с ASCII – первые 128 символов в обеих кодировках совпадают.
Два метода, как поменять шифровку в Word
Ввиду того, что текстовый редактор «Майкрософт Ворд» является самым популярным на рынке, конкретно форматы документов, которые присущи ему, можно почаще всего встретить в сети. Они могут различаться только версиями (DOCX либо DOC). Но даже с этими форматами программа может быть несовместима либо же совместима не полностью.
Случаи неправильного отображения текста
Конечно, когда в програмке наотрез отрешаются раскрываться, казалось бы, родные форматы, это поправить чрезвычайно трудно, а то и фактически нереально. Но, бывают случаи, когда они открываются, а их содержимое нереально прочитать. Речь на данный момент идет о тех вариантах, когда заместо текста, кстати, с сохраненной структурой, вставлены какие-то закорючки, «перевести» которые невозможно.
Эти случаи почаще всего соединены только с одним — с неправильной шифровкой текста. Поточнее, естественно, будет огласить, что шифровка не неправильная, а просто иная. Не воспринимающаяся програмкой. Любопытно еще то, что общего эталона для шифровки нет. То есть, она может различаться в зависимости от региона. Так, создав файл, к примеру, в Азии, быстрее всего, открыв его в Рф, вы не можете его прочитать.
В данной для нас статье речь пойдет конкретно о том, как поменять шифровку в Word. Кстати, это понадобится не лишь только для исправления вышеописанных «неисправностей», но и, напротив, для намеренного неверного кодировки документа.
Определение
Перед рассказом о том, как поменять шифровку в Word, стоит отдать определение этому понятию. На данный момент мы попробуем это сделать обычным языком, чтоб даже дальний от данной нам темы человек все понял.
Зайдем издалека. В «вордовском» файле содержится не текст, как почти всеми принято считать, а только набор чисел. Конкретно они преобразовываются во всем понятные знаки програмкой. Конкретно для этих целей применяется кодировка.
Кодировка — схема нумерации, числовое значение в которой соответствует определенному символу. К слову, шифровка может в себя вмещать не лишь только цифровой набор, но и буковкы, и особые знаки. А ввиду того, что в каждом языке употребляются различные знаки, то и шифровка в различных странах отличается.
Как поменять шифровку в Word. Метод первый
После того, как этому явлению было дано определение, можно перебегать конкретно к тому, как поменять шифровку в Word. 1-ый метод можно выполнить при открытии файла в программе.
В том случае, когда в открывшемся файле вы наблюдаете набор непонятных знаков, это значит, что программа ошибочно определила шифровку текста и, соответственно, не способна его декодировать. Все, что необходимо сделать для корректного отображения каждого знака, — это указать пригодную шифровку для отображения текста.
Говоря о том, как поменять шифровку в Word при открытии файла, для вас нужно сделать следующее:
- Нажать на вкладку «Файл» (в ранешних версиях это клавиша «MS Office»).
- Перейти в категорию «Параметры».
- Нажать по пт «Дополнительно».
- В открывшемся меню пролистать окно до пт «Общие».
- Поставить отметку рядом с «Подтверждать преобразование формата файла при открытии».
- Нажать»ОК».
Итак, полдела изготовлено. Скоро вы узнаете, как поменять шифровку текста в Word. Сейчас, когда вы будете открывать файлы в програмке «Ворд», будет появляться окно. В нем вы можете поменять шифровку открывающегося текста.
Выполните последующие действия:
- Откройте двойным кликом файл, который нужно перекодировать.
- Кликните по пт «Кодированный текст», что находится в разделе «Преобразование файла».
- В появившемся окне установите переключатель на пункт «Другая».
- В выпадающем перечне, что размещен рядом, определите подходящую кодировку.
- Нажмите «ОК».
Если вы избрали верную шифровку, то опосля всего проделанного раскроется документ с понятным для восприятия языком. В момент, когда вы выбираете шифровку, вы сможете поглядеть, как будет смотреться будущий файл, в окне «Образец». Кстати, ежели вы думаете, как поменять шифровку в Word на MAC, для этого необходимо выбрать из выпадающего перечня соответственный пункт.
Способ второй: во время сохранения документа
Суть второго метода достаточно проста: открыть файл с неправильной шифровкой и сохранить его в пригодной. Делается это последующим образом:
- Нажмите «Файл».
- Выберите «Сохранить как».
- В выпадающем перечне, что находится в разделе «Тип файла», выберите «Обычный текст».
- Кликните по «Сохранить».
- В окне преобразования файла выберите предпочитаемую шифровку и нажмите «ОК».
Теперь вы понимаете два метода, как можно поменять шифровку текста в Word. Надеемся, что эта статья посодействовала для вас в решении вопроса.
Откуда берутся ошибки?
Государственная кадастровая оценка – это трудоемкая процедура, которая с момента принятия решения о проведении оценки до утверждения результатов может длиться полтора года (п. 7 ст. 11 Закона № 237-ФЗ).
При определении кадастровой стоимости используются методы массовой оценки, при которых осуществляется построение единых для групп объектов недвижимости, имеющих схожие характеристики, расчетных моделей3. Рассчитывается кадастровая стоимость на основании общедоступной статистической и рыночной информации. Но такой способ не позволяет учесть все ценообразующие характеристики каждого объекта недвижимости. Это достижимо только в рамках индивидуальной оценки.
Как в Windows 10 убрать кракозябры вместо русских букв, 2 способа исправления
Кракозябры, или иероглифы, вместо русских букв в Windows 10 появляются зачастую после установки операционной системы. Непонятные символы встречаются в документах. Кириллица искаженно транслируется, если пользователь воспользовался не совсем лицензированной или английской версией Виндовса. Это самые распространенные причины неполадки, которые исправит любой человек.
Причины отображения иероглифов вместо русских букв
Обычно проблемы с кодировкой встречаются не во всех текстовых файлах и установщиках программного обеспечения сразу. Например, при открытии инсталлера ПО его название корректно, а вот содержимое неправильно отображается. Или при написании текста в «блокноте» появляются вопросы и кракозябры.
К причинам некорректного отображения кириллицы относят:
- Ошибка русификации приложений.
- Сбой обновлений.
- Использование английской версии операционной системы.
- Установка взломанной Windows 10.
Пользователи спешат исправить неполадки простой переустановкой ОС. Но это не всегда помогает. Особенно, если проблема заключается не в Виндовсе.
Частый вопрос от пользователей – почему в ОС Windows 10 в известной программе «Налогоплательщик ЮЛ» отображаются иероглифы и кракозябры. Данная проблема решается просто: в шрифтовую систему устанавливают MS Sans Serif.
Методы исправления проблемы
Есть 2 метода, которые помогают убрать каракули в текстовых файлах и программах Виндовс 10. Первый вариант – смена языка системы. Он простой. Вариант посложнее — подмена файла кодовой страницы.
Изменение языка системы
За отображение текста в программном обеспечении системы и сторонних приложений отвечает настройка в Панели управления с названием «Региональные стандарты». Убрать каракули со знаками вопроса можно через редактирование настроек:
Заходим в «Пуск», кликаем на «Панель управления».
Выбираем пункт под названием «Региональные стандарты».
Перед пользователем высвечивается меню, в котором он кликает на вкладку «Дополнительно», а дальше – на кнопку изменения языка ОС.
Нужно убедиться, что в настройках стоит русский язык. Если нет – меняем настройку на нужную конфигурацию. После этого нажимаем «Окей».
Для того чтобы исправления подействовали, и исчезли некорректные вопросительные символы, перезапускаем персональный компьютер. Система предупредит об этом.
После перезагрузки пользователь проверяет, подействовал метод исправления ошибки или нет. Если же операция не принесла успеха, пробуют следующий способ.
Путем подмены файла кодовой страницы на c_1251.nls
Данный метод практически всегда помогает убрать непонятные символы и восстановить отображение кириллицы. Для этого на пути «C:WindowsSystem32» подменяют файл кодовой страницы. Способ эффективен, если пользователь уверен, что система использует кодовую страницу со значением 1252. Алгоритм действий:
В папке «System32» находим файл с названием «c_1251.nls». Кликаем правой кнопкой мышки и выбираем «Свойства», далее – вкладку «Безопасность».
В дополнительных параметрах безопасности меняем настройки в разделе «Владелец».
В разделе «Администраторы» включаем полный доступ. Соглашаемся с изменениями.
Возвращаемся в открытую директорию, редактируем файл «c_1251.nls». Необходимо поменять расширение «NLS» на «TXT».
- После зажимают на клавиатуре клавишу «CTRL» и перетаскивают файл вверх для создания его копии.
- В конце созданную копию переименовывают в «NLS». С этого момента можно считать, что некорректные каракули в программах и текстах исчезли.
Восстановить отображение кириллицы на Виндовс 10 легко и просто. Главное – знать причину появления проблемы. Не рекомендуется просто переустанавливать Windows. Скорее всего, данный метод не поможет.
Юникод
Нетрудно понять, что, хотя кодирование важно, декодирование в равной степени жизненно важно для понимания представлений. Это возможно на практике только в том случае, если широко используется согласованная или совместимая схема кодирования
Различные схемы кодирования, разработанные изолированно и практикуемые в местных географических регионах, начали становиться сложными.
Эта проблема породила особый стандарт кодирования, называемый Unicode, который имеет емкость для всех возможных символов в мире . Это включает в себя символы, которые используются, и даже те, которые уже не существуют!
Ну, для этого должно потребоваться несколько байтов для хранения каждого символа? Честно говоря, да, но у Unicode есть гениальное решение.
Unicode как стандарт определяет кодовые точки для каждого возможного символа в мире. Кодовая точка для символа “T” в Юникоде равна 84 в десятичной системе счисления. Обычно мы называем это “U+0054” в Юникоде, который представляет собой не что иное, как U+, за которым следует шестнадцатеричное число.
Мы используем шестнадцатеричную систему в качестве основы для кодовых точек в Юникоде, поскольку существует 1 114 112 точек, что является довольно большим числом для удобной передачи в десятичном формате!
То, как эти кодовые точки кодируются в биты, зависит от конкретных схем кодирования в Юникоде. Мы рассмотрим некоторые из этих схем кодирования в подразделах ниже.
5.1. UTF-32
UTF-32-это схема кодирования для Unicode, которая использует четыре байта для представления каждой кодовой точки , определенной Unicode. Очевидно, что использование четырех байтов для каждого символа неэффективно.
Давайте посмотрим, как простой символ, такой как “T”, представлен в UTF-32. Мы будем использовать метод преобразования в двоичный код , введенный ранее:
assertEquals(convertToBinary("T", "UTF-32"), "00000000 00000000 00000000 01010100");
Вывод выше показывает использование четырех байтов для представления символа “T”, где первые три байта-это просто потраченное впустую пространство.
5.2. UTF-8
UTF-8-это другая схема кодирования для Unicode, которая использует переменную длину байтов для кодирования . Хотя он обычно использует один байт для кодирования символов, при необходимости он может использовать большее количество байтов, что экономит место.
Давайте снова вызовем метод convertToBinary с вводом как “T” и кодированием как ” UTF-8″:
assertEquals(convertToBinary("T", "UTF-8"), "01010100");
Вывод в точности аналогичен ASCII, использующему только один байт. На самом деле UTF-8 полностью обратно совместим с ASCII.
Давайте снова вызовем метод convertToBinary с вводом как “語” и кодированием как ” UTF-8″:
assertEquals(convertToBinary("語", "UTF-8"), "11101000 10101010 10011110");
Как мы видим здесь, UTF-8 использует три байта для представления символа “語”. Это известно как кодирование переменной ширины .
UTF-8, благодаря своей экономичности пространства, является наиболее распространенной кодировкой, используемой в Интернете.
Кодирование и декодирование
Кодирование— это процесс формирования определенного представления информации,переход от одной формы представления информации к другой, более удобной для хранения, передачи или обработки.То есть любой символ, который мы видим или вводим, для компьютера в реальности — всего лишь набор битов (набор нулей и единиц). Именно эти биты и перегоняются от устройства к устройству. А чтобы показать результат этих перегонок человеку, компьютер преобразует с помощью таблицы (той самой кодировки) код символа в соответствующий внешний вид.
UTF-32LE в UTF-8
Схемой можете воспользоваться при кодировании и раскодировании.
Эта схема сделана так, чтобы вы видели какие биты куда попадают как при кодировании, так и раскодировании.
По ней видно что при этих обоих процессах просто нужные биты выставляются на нужные позиции при нужных значениях контрольных бит.
Можно заметить что компоновка в больших байтовых последовательностях осуществляется по 6 бит (в так называемых лидирующих байтах).
При этом старшие биты предусматриваемого кода будут в первых байтах (схоже с порядком Big-Endian).
Кодирование
Порядок действий такой:
- Каждый символ превращаем в Unicode.
- Проверяем из какого диапазона символ.
- Если код символа меньше 128, то к результату добавляем его в неизменном виде.
- Если код символа меньше 2048, то берем последние 6 бит и первые 5 бит кода символа. К первым 5 битам добавляем 0xC0 и получаем первый байт последовательности, а к последним 6 битам добавляем 0x80 и получаем второй байт. Конкатенируем и добавляем к результату.
- Похожим образом можем продолжить и для больших кодов, но если символ за пределами U+FFFF придется иметь дело с UTF-16 суррогатами.
Function EncodeUTF8(s)
Dim i, c, utfc, b1, b2, b3
For i=1 to Len(s)
c = ToLong(AscW(Mid(s,i,1)))
If c < 128 Then
utfc = chr( c)
ElseIf c < 2048 Then
b1 = c Mod &h40
b2 = (c - b1) &h40
utfc = chr(&hC0 + b2) & chr(&h80 + b1)
ElseIf c < 65536 And (c < 55296 Or c > 57343) Then
b1 = c Mod &h40
b2 = ((c - b1) &h40) Mod &h40
b3 = (c - b1 - (&h40 * b2)) &h1000
utfc = chr(&hE0 + b3) & chr(&h80 + b2) & chr(&h80 + b1)
Else
' Младший или старший суррогат UTF-16
utfc = Chr(&hEF) & Chr(&hBF) & Chr(&hBD)
End If
EncodeUTF8 = EncodeUTF8 + utfc
Next
End Function
Function ToLong(intVal)
If intVal < Then
ToLong = CLng(intVal) + &H10000
Else
ToLong = CLng(intVal)
End If
End Function
Декодирование
Декодирование — преобразование зашифрованной информации в понятный, пригодный для непосредственного использования вид.
- Ищем первый символ вида 11xxxxxx
- Считаем все последующие байты вида 10xxxxxx
- Если последовательность из двух байт и первый байт вида 110xxxxx, то отсекаем приставки и складываем, умножив первый байт на 0x40.
- Аналогично для более длинных последовательностей.
- Заменяем всю последовательность на нужный символ Unicode.
Function DecodeUTF8(s)
Dim i, c, n, b1, b2, b3
i = 1
Do While i <= len(s)
c = asc(mid(s,i,1))
If (c and &hC0) = &hC0 Then
n = 1
Do While i + n <= len(s)
If (asc(mid(s,i+n,1)) and &hC0) <> &h80 Then
Exit Do
End If
n = n + 1
Loop
If n = 2 and ((c and &hE0) = &hC0) Then
b1 = asc(mid(s,i+1,1)) and &h3F
b2 = c and &h1F
c = b1 + b2 * &h40
Elseif n = 3 and ((c and &hF0) = &hE0) Then
b1 = asc(mid(s,i+2,1)) and &h3F
b2 = asc(mid(s,i+1,1)) and &h3F
b3 = c and &h0F
c = b3 * &H1000 + b2 * &H40 + b1
Else
' Символ больше U+FFFF или неправильная последовательность
c = &hFFFD
End if
s = left(s,i-1) + chrw( c) + mid(s,i+n)
Elseif (c and &hC0) = &h80 then
' Неожидаемый продолжающий байт
s = left(s,i-1) + chrw(&hFFFD) + mid(s,i+1)
End If
i = i + 1
Loop
DecodeUTF8 = s
End Function
Если кодировка не отображается
Если вы зашли на чужой сайт с абракадаброй, а вам все равно очень интересно почитать контент, то в Справке Google объясняют, как исправить кодирование текста через браузер.
О проблеме возникновения абракадабры на вашем сайте будут сигнализировать метрики поведения: вырастут отказы, уменьшится глубина просмотров. Но скорее всего вы и раньше заметите, что что-то пошло не так.
Главное правило — для всех файлов, скриптов, баз данных сайта и сервера должна быть указана одна кодировка. Ошибка может возникнуть, если вы случайно указали на сайте разные виды кодировки.
Яндекс советует использовать одинаковую кодировку для страниц и кириллических адресов структуры. К примеру, если робот встретит ссылку href=»/корзина» на странице с кодировкой UTF-8, он сохранит ее в этом же UTF-8, так что страница должна быть доступна по адресу «/%D0%BA%D0%BE%D1%80%D0%B7%D0%B8%D0%BD%D0%B0».
Когда начинает применяться измененная кадастровая стоимость?
Закон № 269-ФЗ не только перекроил порядок определения и пересмотра кадастровой стоимости, но и внес существенные изменения в правила применения стоимости в случае ее пересмотра или изменения. Так, после исправления ошибки новая кадастровая стоимость будет применяться:
- с начала применения ошибочной стоимости в случае ее уменьшения (подп. «б» п. 3 ст. 18 Закона № 237-ФЗ);
- с 1 января года, следующего за годом, когда ошибка была исправлена, в случае увеличения кадастровой стоимости (п. 2 ст. 18 Закона № 237-ФЗ).
Стоит отметить, что более ранняя редакция Закона № 237-ФЗ, действовавшая до 11 августа 2020 г., не допускала пересчета кадастровой стоимости в сторону увеличения при исправлении ошибки.
Лучшие сайты
Рассмотрим наиболее эффективные конвертеры символов, работающие с привычной кириллицей. Большинство из них можно использовать в режиме «по умолчанию» благодаря встроенному алгоритму расшифровки, но при надобности можно применять ручные настройки.
Универсальный декодер — конвертер кириллицы
Этот сервис наиболее популярен среди пользователей рунета. Найти можно по адресу 2cyr.com. Для работы с ним нужно скопировать подлежащий декодированию текст и вставить в предназначенное для этого поле. Нужно разместить копируемый отрывок так, чтобы уже на его первой строке встречались «кракозябры». Если пользователь хочет, чтобы сервис распознал кодировку автоматически, нужно указать это в выпадающем списке выбора. Но возможна и ручная настройка с указанием нужного типа. Закодированный фрагмент будет доступен в блоке «Результат».
Однако сервис, при всей своей простоте и возможности выбора, имеет и ограничения. Если поместить в поле текст объемом более 100 Кб сервис не сможет обработать его, так что длинные фрагменты придется декодировать по кусочкам.
Декодер Артемия Лебедева
Этот дешифратор работает со всеми кодировками с которыми может столкнуться пользователь, работающий с кириллицей.
Декодер Лебедева включает в себя простой и сложный (с дополнительными настройками) режимы работы. В режиме «Сложно» отображается не только исходный текст, но и преобразованный. Также можно выбрать кодировку, в которую требуется перевести текст, из выпадающего списка. Декодированный фрагмент доступен для прочтения и копирования в правом блоке.
Fox Tools
Как и в случае с предыдущими, пользователю Fox Tools предоставляется возможность выбрать конечный результат. Сервис может работать и в режиме «по умолчанию», применяющемся в случае неизвестной желаемой кодировки, но тогда все равно придется выбирать вручную вариант результирующего текста, наиболее отвечающий его цели. Сервис имеет весьма простой и понятный дизайн интерфейса, что делает его подходящим для людей с низким уровнем компьютерной грамотности.
Translit.net
Сервис Translit, напротив, не отличается лаконичностью внешнего вида, но принцип работы с ним такой же, как и у других онлайн-декодеров. Нужно ввести текст и вручную установить желаемые настройки.
Положительные стороны раскодировки
Реабилитация после раскодирования может пройти с успехом, если у пациента будет поддержка со стороны родных и близких. Даже без кодирования в таких случаях у пациентов редко возникает желание возврата к прошлой жизни, так как меняется жизнь человека:
- через какое-то время возникают привычки, не связанные с употреблением алкогольных напитков;
- отсутствует необходимость самоконтроля;
- улучшается физическое состояние из-за обновления крови, восстановления внутренних органов;
- появляется возможность употребления пищи с незначительными дозами алкоголя;
- налаживаются отношения с близкими, друзьями и в кругу семьи.
Все эти факторы позволяют обеспечить возврат к качеству жизни, которая была у пациента ранее, до увлечения спиртными напитками.
Вероятность развития осложнений после кодирования
Патологические состояния после кодировки от алкоголизма связаны с наличием у пациента хронических заболеваний. Например, пьющий человек жаловался на перебои в работе сердечнососудистой системы. Скорее всего, именно на сосуды и сердце придется основной удар в процессе антиалкогольной терапии. Наиболее вероятные осложнения, которые могут развиться после кодирования от алкогольной зависимости:
- Снижение половой активности и либидо;
- Обострение сердечных заболеваний, риск развития инфаркта или инсульта;
- Угнетение деятельности почек и печени;
- Ухудшение работы органов ЖКТ и снижение интенсивности многих метаболических процессов;
- Развитие тревожных состояний, появление паники;
- Депрессивные расстройства, ослабление интереса к жизни.
При появлении хотя бы одного из перечисленных выше состояний пациента необходимо показать медикам. Опытный нарколог и психиатр скорректируют схему лечения, помогут безболезненно устранить возникшие симптомы. Комплексный подход – гарантия успешного завершения реабилитационного периода после алкогольной кодировки.
Исправляем отображение русских букв в Windows 10
Существует два способа решения рассматриваемой проблемы. Связаны они с редактированием настроек системы или определенных файлов. Они отличаются по сложности и эффективности, поэтому мы начнем с легкого. Если первый вариант не принесет никакого результата, переходите ко второму и внимательно следуйте описанным там инструкциям.
Способ 1: Изменение языка системы
В первую очередь хотелось бы отметить такую настройку как «Региональные стандарты». В зависимости от его состояния и производится дальнейшее отображение текста во многих системных и сторонних программах. Редактировать его под русский язык можно следующим образом:
- Откройте меню «Пуск» и в строке поиска напечатайте «Панель управления». Кликните на отобразившийся результат, чтобы перейти к этому приложению.
Среди присутствующих элементов отыщите «Региональные стандарты» и нажмите левой кнопкой мыши на этот значок.
Появится новое меню с несколькими вкладками. В данном случае вас интересует «Дополнительно», где нужно кликнуть на кнопку «Изменить язык системы…».
Корректировки вступят в силу только после перезагрузки ПК, о чем вы и будете уведомлены при выходе из меню настроек.
Дождитесь перезапуска компьютера и проверьте, получилось ли исправить проблему с русскими буквами. Если нет, переходите к следующему, более сложному варианту решения этой задачи.
Способ 2: Редактирование кодовой страницы
Кодовые страницы выполняют функцию сопоставления символов с байтами. Существует множество разновидностей таких таблиц, каждая из которых работает с определенным языком. Часто причиной появления кракозябров является именно неправильно выбранная страница. Далее мы расскажем, как править значения в редакторе реестра.
- Нажатием на комбинацию клавиш Win + R запустите приложение «Выполнить», в строке напечатайте regedit и кликните на «ОК».
- В окне редактирования реестра находится множество директорий и параметров. Все они структурированы, а необходимая вам папка расположена по следующему пути:
Выберите «CodePage» и опуститесь в самый низ, чтобы отыскать там имя «ACP». В столбце «Значение» вы увидите четыре цифры, в случае когда там выставлено не 1251, дважды кликните ЛКМ на строке.
Двойное нажатие левой кнопкой мыши открывает окно изменения строковой настройки, где и требуется выставить значение 1251 .
Если же значение и так уже является 1251, следует провести немного другие действия:
- В этой же папке «CodePage»поднимитесь вверх по списку и отыщите строковый параметр с названием «1252»Справа вы увидите, что его значение имеет вид с_1252.nls. Его нужно исправить, поставив вместо последней двойки единицу. Дважды кликните на строке.
Откроется окно редактирования, в котором и выполните требуемую манипуляцию.
После завершения работы с редактором реестра обязательно перезагрузите ПК, чтобы все корректировки вступили в силу.
Подмена кодовой страницы
Некоторые пользователи не хотят править реестр по определенным причинам либо же считают эту задачу слишком сложной. Альтернативным вариантом изменения кодовой страницы является ее ручная подмена. Производится она буквально в несколько действий:
- Откройте «Этот компьютер»и перейдите по пути C:WindowsSystem32 , отыщите в папке файл С_1252.NLS, кликните на нем правой кнопкой мыши и выберите «Свойства».
Переместитесь во вкладку «Безопасность» и найдите кнопку «Дополнительно».
Вам нужно установить имя владельца, для этого кликните на соответствующую ссылку вверху.
В пустом поле впишите имя активного пользователя, обладающего правами администратора, после чего нажмите на «ОК».
Вы снова попадете во вкладку «Безопасность», где требуется откорректировать параметры доступа администраторов.
Выделите ЛКМ строку «Администраторы» и предоставьте им полный доступ, установив галочку напротив соответствующего пункта. По завершении не забудьте применить изменения.
Вернитесь в открытую ранее директорию и переименуйте отредактированный файл, поменяв его расширение с NLS, например, на TXT. Далее с зажатым CTRL потяните элемент «C_1251.NLS» вверх для создания его копии.
Нажмите на созданной копии правой кнопкой мыши и переименуйте объект в C_1252.NLS.
Вот таким нехитрым образом происходит подмена кодовых страниц. Осталось только перезапустить ПК и убедиться в том, что метод оказался эффективным.
Как видите, исправлению ошибки с отображением русского текста в операционной системе Windows 10 способствуют два достаточно легких метода. Выше вы были ознакомлены с каждым. Надеемся, предоставленное нами руководство помогло справиться с этой неполадкой.
Способ 1: 2cyr
Онлайн-сервис 2cyr поддерживает практически все популярные кодировки, а также позволяет исправить запись разными способами в зависимости от известной о кодировке информации. Для преобразования текста в читабельный вид при помощи данного сайта осуществите следующие действия:
- Воспользуйтесь ссылкой выше, чтобы открыть главную страницу сайта 2cyr. Кликните по соответствующему полю для его активации.
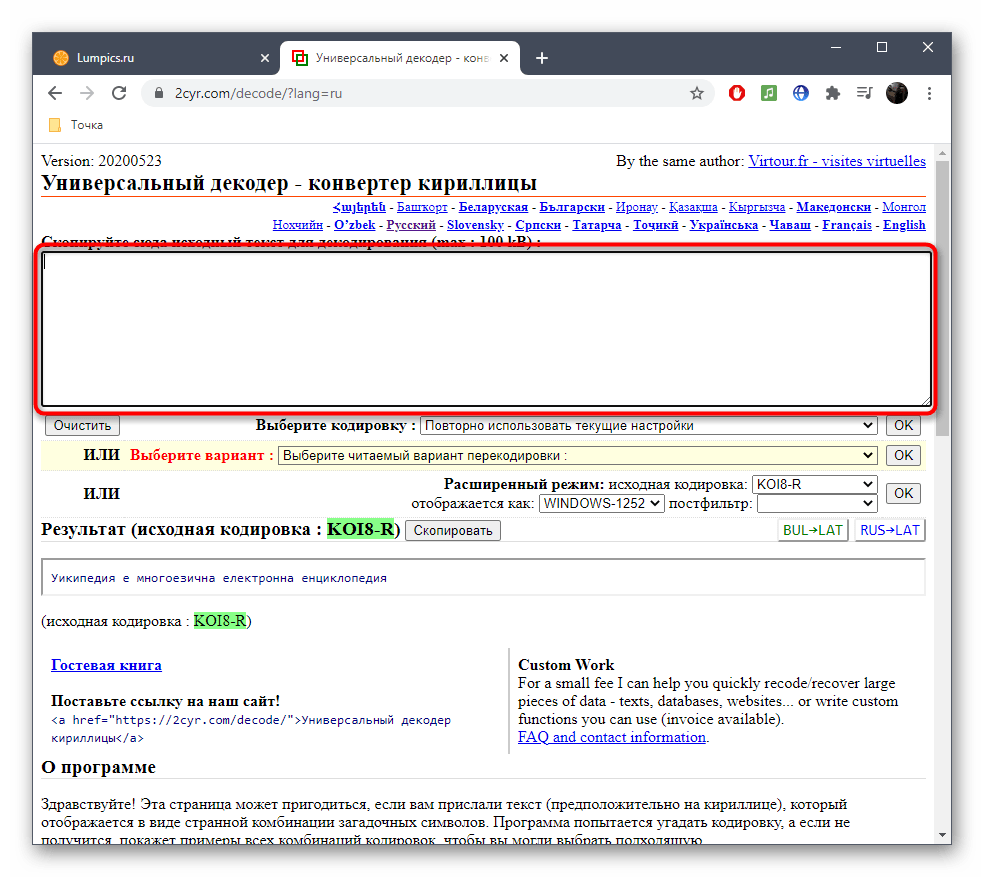
Скопируйте текст в неверной кодировке и вставьте его в данное поле. Для этого можно использовать стандартные сочетания клавиш Ctrl + C и Ctrl + V.
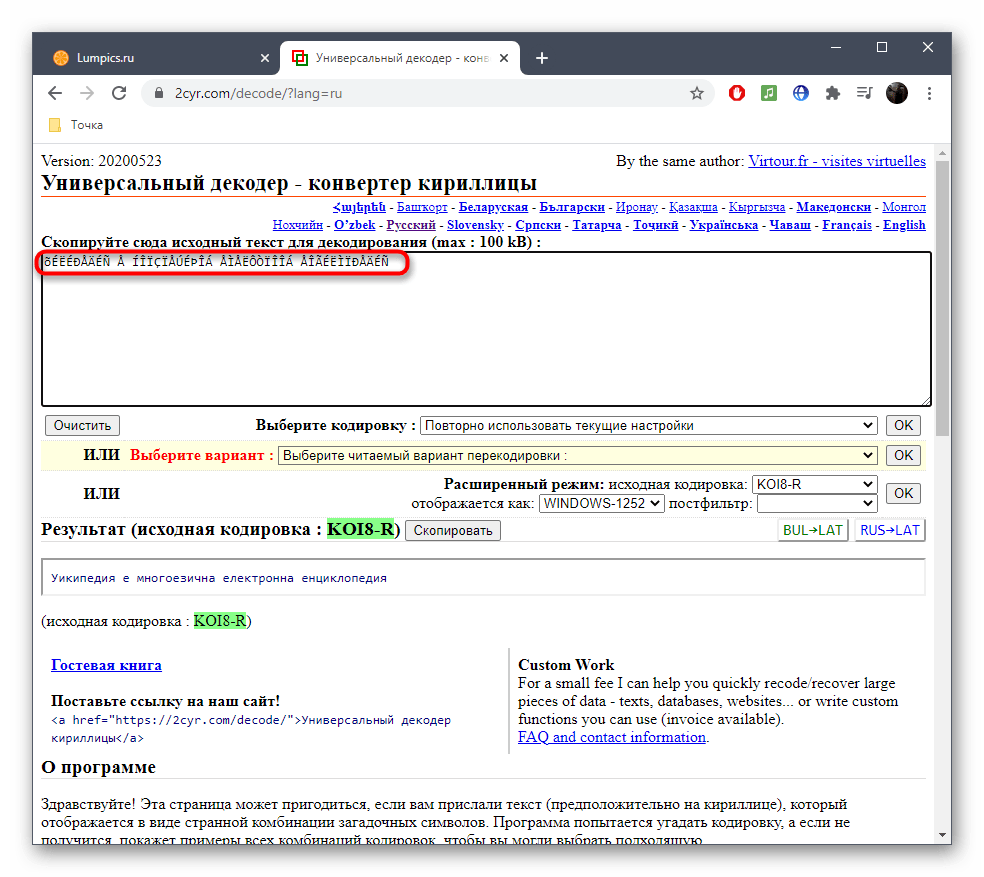
Если известен формат поврежденной кодировки, его можно сразу же выбрать в отдельном меню, чтобы получить правильное исправление.
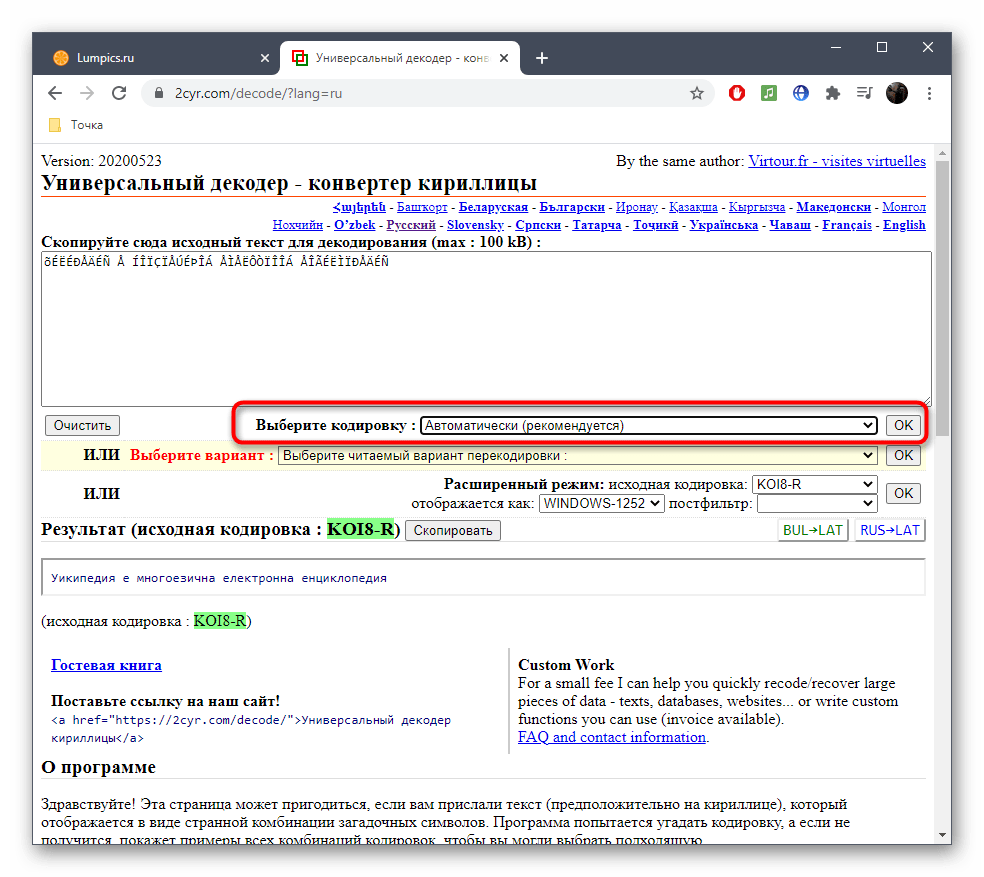
Второй вариант декодирования подразумевает просмотр результата на всех присутствующих в онлайн-сервисе кодировках. Для этого надо развернуть выпадающее меню и найти там читаемый вариант.
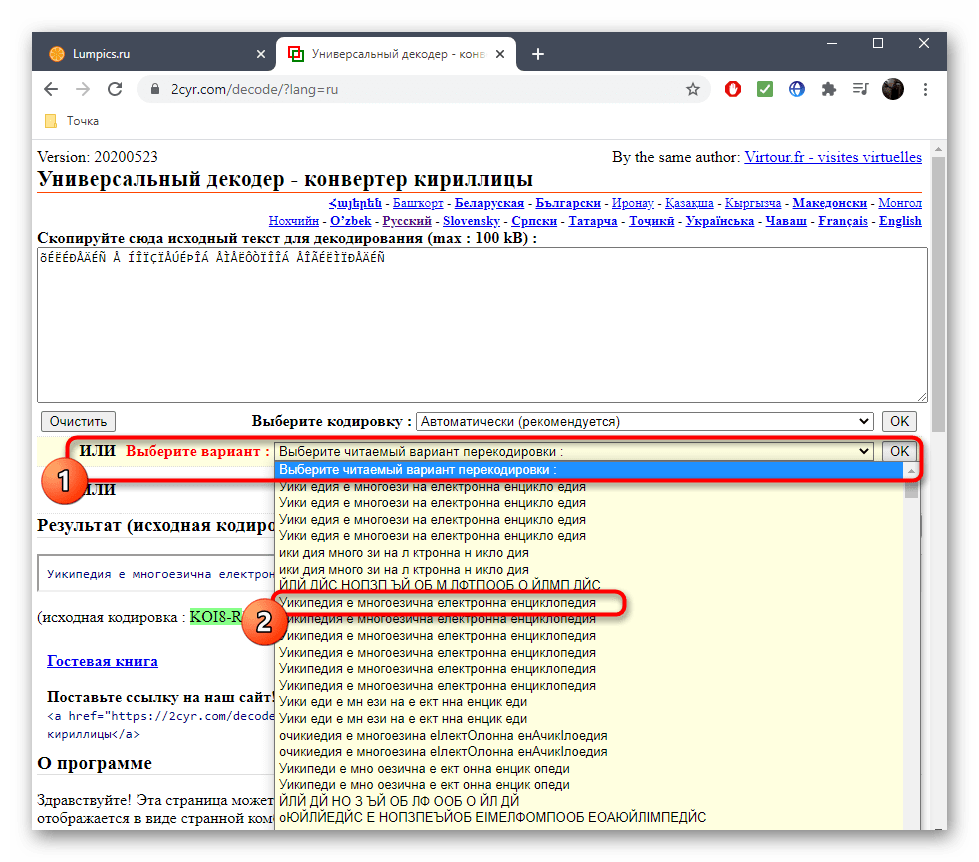
После этого подтвердите свой выбор, кликнув «ОК», ведь только так можно скопировать готовый текст.
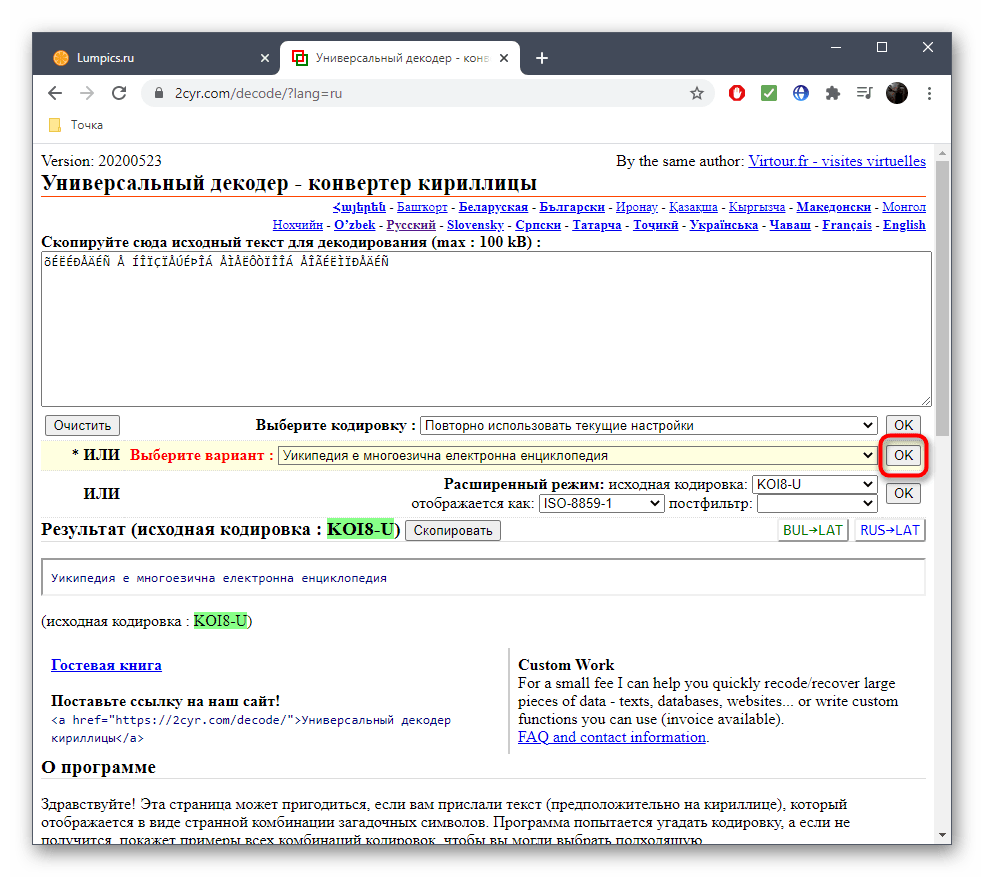
Он будет отображаться внизу и доступен для копирования. Выделите его зажатой левой кнопкой мыши и используйте упомянутые выше комбинации, чтобы скопировать и вставить в необходимый текстовый документ.
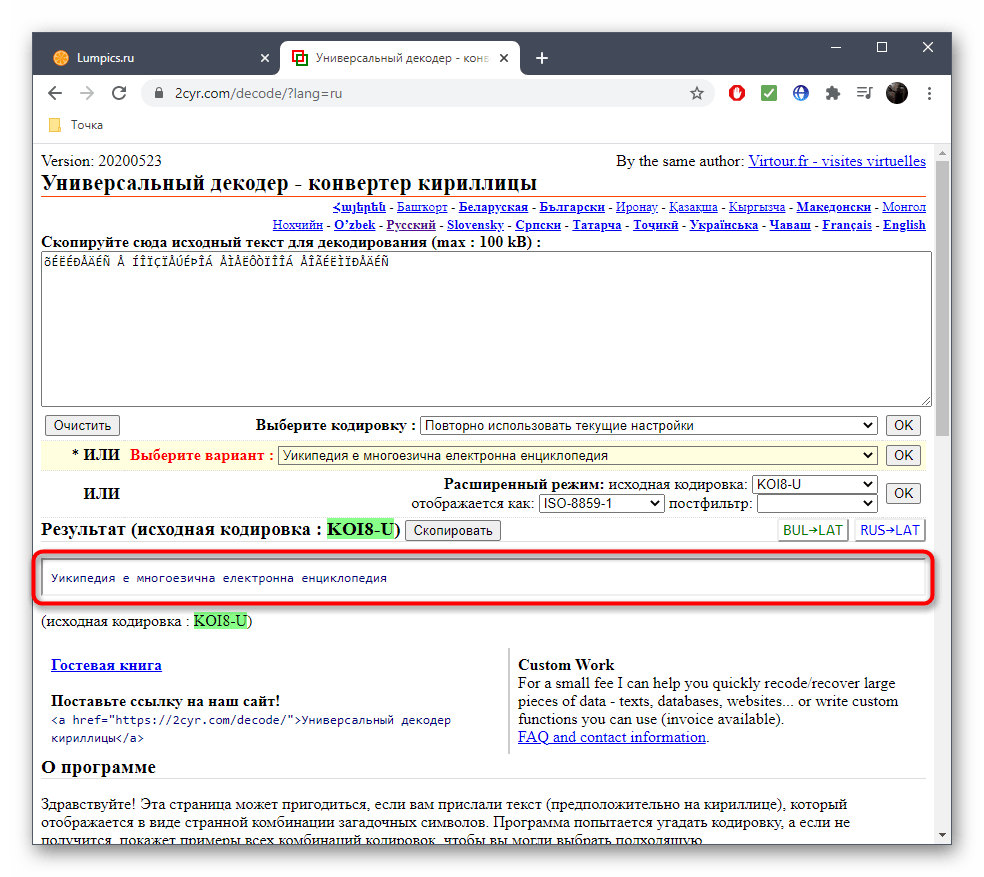
Исходную кодировку вы видите выше — она отмечена зеленым цветом. Иногда это нужно пользователям при ее декодировании.
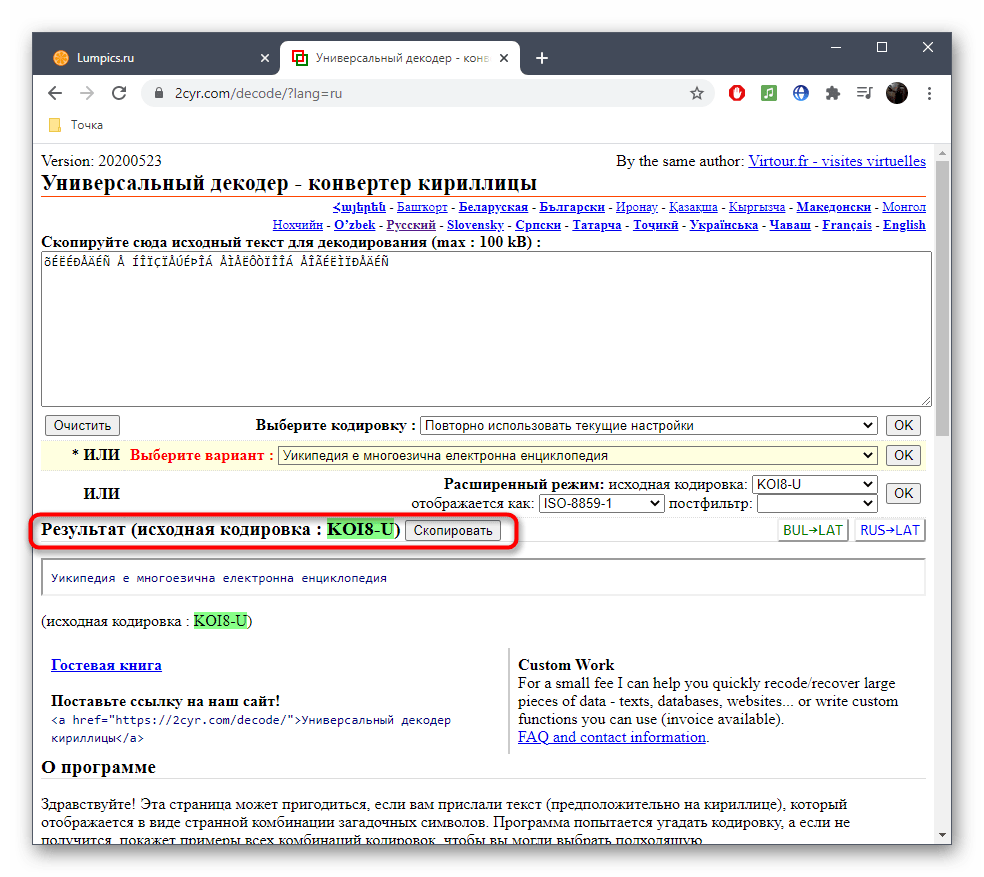
Данный сайт корректно исправляет любую кодировку, которая есть в списке поддерживаемых, поэтому вы можете взять его на вооружение и использовать в любой момент по необходимости.