Как удалить повторяющиеся строки
Содержание:
- Auslogics Duplicate File Finder
- Лучший инструмент, который вы, возможно, уже установили: CCleaner
- Хранилище внешних отчетов и обработок (интегрируемый модуль)
- Универсальные приложения
- Удаление повторяющихся строк
- Удаление
- Поиск и удаление дублей на CMS WordPress
- Причины возникновения дублей на сайте
- Обработка найденных дубликатов
- Удаление одинаковых значений таблицы в Excel
- Использование набора ()
- Результаты
- Функция удаления дубликатов
- Метод 3: использование фильтра
- Поиск дубликатов при помощи встроенных фильтров Excel
Auslogics Duplicate File Finder
Программа Auslogics Duplicate File Finder — также бесплатная и хорошо решает вопрос о том, как удалить дубликаты файлов, т.е. она способна находить лишние копии музыкальных файлов, фильмов, изображений и т.д. Поиск дубликатов программа ведет, сравнивая хеш MD5.
Интерфейс приложения интуитивно понятен — после запуска программы пользователю предлагается выбрать тип файлов для сканирования (архивы, программы, фотографии и т.д.), а после сканирования остается лишь удалить ненужные копии. Единственный минус программы в том, что она время от времени показывает навязчивую рекламу.
И давайте рассмотрим эту программу более детально.
Auslogics Duplicate File Finder работает в операционной системе Windows, быстро скачивается и настраивается. При необходимости ее в любой момент можно удалить.
Утилита позволяет выборочно и быстро сканировать диски компьютера. В конечном итоге программа выдает результат в виде наглядной таблицы, где можно решить – удалять или не удалять найденные дублированные файлы.
Установка и настройка программыAuslogics Duplicate File Finder.
Установка довольно проста и примитивна. Во время установки соглашаемся принять лицензионное соглашение, поставив галочку у пункта «I accept the agreement».
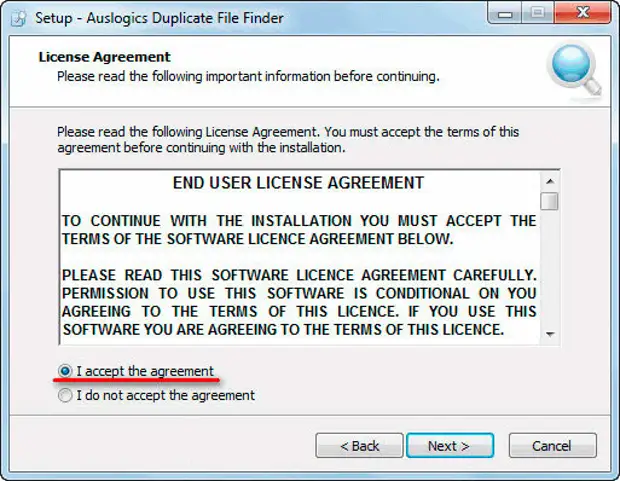
Далее нажимаем только на кнопку «Next». После того, как программа будет установлена на компьютер перейдем к настройке и, непосредственно, к поиску.
На рисунке ниже в левой колонке выбираем и отмечаем диски (если есть внешний жесткий диск или флешка, можно подключить и их) и даже папки, в которых будем производить сканирование.
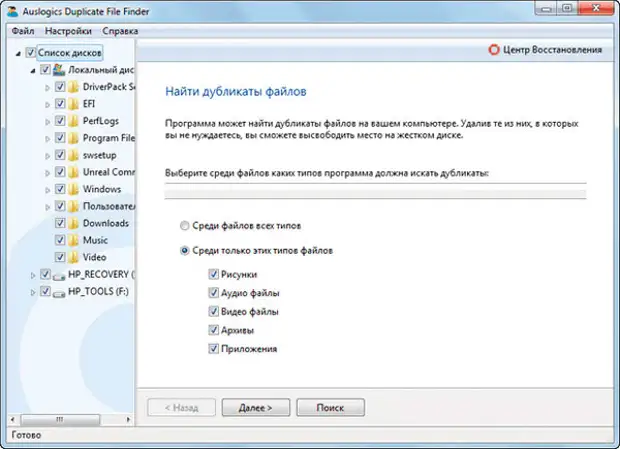
В правой колонке выбираем типы файлов поиска. По умолчанию галочки стоят«Среди только этих типов файлов» (Рисунки, Аудио файлы, Видео файлы, Архивы, Приложения).
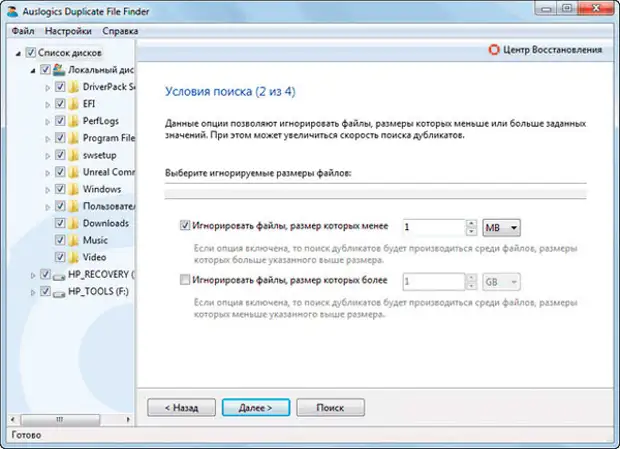
Начинающим пользователям рекомендуется оставлять все как есть, дабы не удалить лишнее, выбрав пункт «Среди файлов всех типов». Затем жмем на кнопку «Далее». В следующем окне ставим фильтр на размер файла и жмем кнопку «Далее».
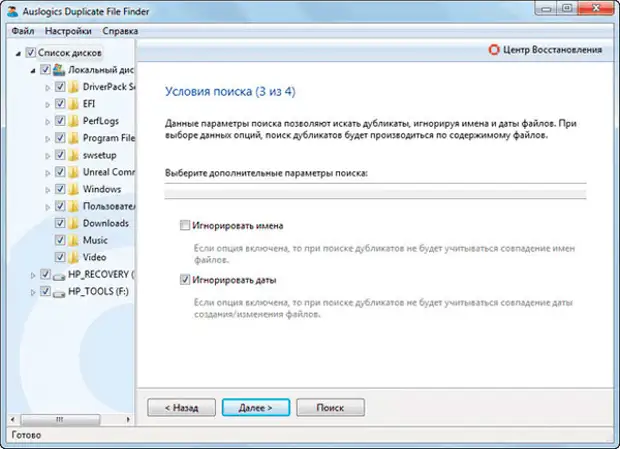
Затем нам предлагают поставить фильтр на имена и даты, после жмем кнопку«Далее».
В следующем окне программа (по умолчанию) будет удалять файлы в корзину. Если поставить галочку «В центр Восстановления», то тогда файлы будут архивироваться и их можно будет потом восстановить. Для начинающих пользователей этот метод в самый раз. Опытные юзеры могут и из корзины восстановить, если что.
Ну, а если выбрать пункт «Безвозвратно», то тогда файлы канут в бездну, т.е. удаляться безвозвратно. После выбора места удаления жмем на кнопку«Поиск».
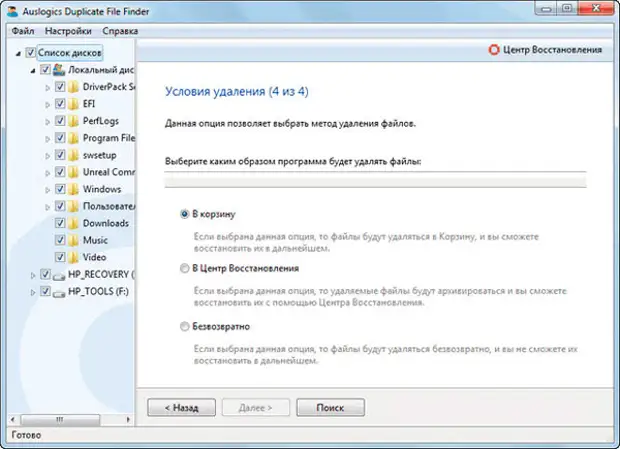
Обычно поиск занимает несколько минут. Далее можно выбрать вручную дублированные файлы для удаления или воспользоваться имеющимися подпунктами в кнопке «Выбрать». После того, как вы определились с файлами для удаления, переходим к финальной части и жмем на кнопку «Удалить выбранные файлы».
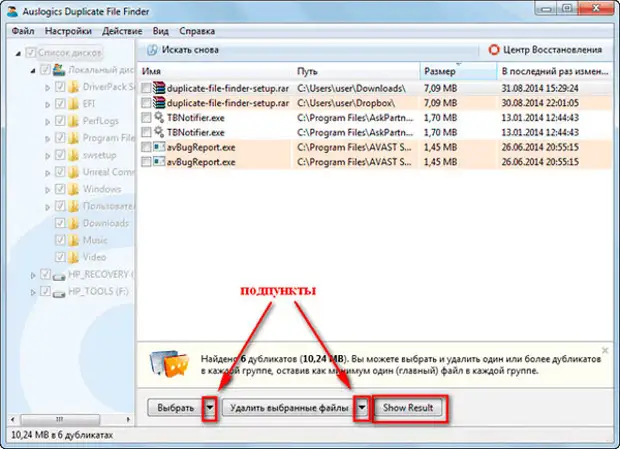
После завершения операции в программе можно ознакомиться с результатами. Для этого нажимаем на кнопку «ShowResult». Будет показан краткий анализ.
Восстановление удаленных файлов.
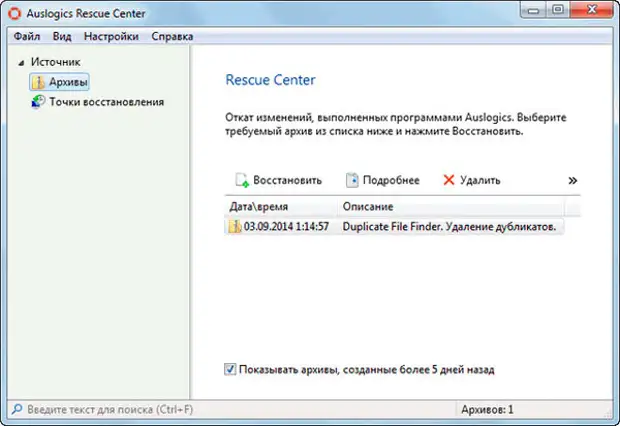
Может случиться и так, что вы по ошибке удалили нужные файлы. Для того чтобы их восстановить поможет инструмент «Центр восстановления», с учетом того, что раньше был создан архив.
«Центр восстановления» можно задействовать как через меню «Файл», так и через непосредственную кнопку в правом верхнем углу программы Auslogics Duplicate File Finder.
На этом пока все! Надеюсь, что вы нашли в этой заметке что-то полезное и интересное для себя.
Лучший инструмент, который вы, возможно, уже установили: CCleaner
CCleaner — это популярный инструмент, поэтому есть большая вероятность, что он уже установлен, тем более, что мы писали о нем статью. Главная особенность CCleaner — это средство для удаления ненужных файлов, которое освобождает место на жестком диске, удаляя ненужные временные файлы, но также имеет немало других встроенных инструментов, включая средство поиска дубликатов файлов.
Запустите CCleaner и нажмите «Инструменты > Поиск дубликатов», чтобы найти эту функцию нужную функцию. Он доступен во всех версиях CCleaner, поэтому вам не нужно платить за использование CCleaner Pro.
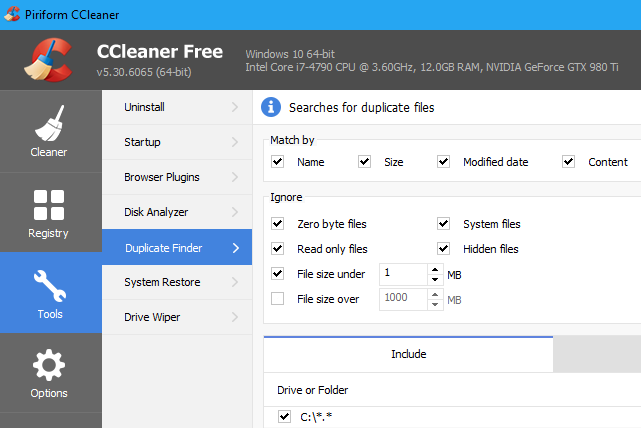
Настройки CCleaner по умолчанию разумны и позволят вам искать дубликаты файлов на диске C:, игнорируя системные и скрытые файлы. Вы также можете выбрать поиск в определенном каталоге, нажав кнопку «Добавить» на панели «Включить» и выбрав эту папку. Не забудьте выбрать опцию «Включить файлы и подпапки» при добавлении новой папки, чтобы CCleaner осуществлял поиск любых папок в указанной вами папке.
Интерфейс этого инструмента для просмотра дубликатов файлов не изящен, и не имеет все те же параметры предварительного просмотра Auslogics Duplicate File Finder делает. Тем не менее, он позволяет Вам легко выбирать, какие файлы вы хотите удалить, и даже сохранять список дубликатов в текстовый файл, но это базовый интерфейс, который позволяет вам выбрать, какие файлы вы хотите удалить, и даже сохранить список дубликатов файлов в текстовый файл. Вы можете щелкнуть правой кнопкой мыши файл в списке и выбрать «Открыть папку», если вы хотите просмотреть сам файл в своей системе.
Хранилище внешних отчетов и обработок (интегрируемый модуль)
Сие идея по принципу хранилища конфигурации была реализована для удобства и надежности совместной работы программистов с внешними отчетами и обработками для БСП справочника «Дополнительные отчеты и обработки»: все файлы ВОиО для спр. ДОиО всех подключенных ИБ хранятся и учитываются в одном месте; возможность захвата/освобождения файла ВОиО; создание версий с комментариями (добавление новой или обновление текущей); признак проверенности (для связки работы с аналитиком); проверочный механизм совместимости версий файла ВОиО и конфигурации; быстрое переключение между версиями.
3 стартмани
Универсальные приложения
Универсальные приложения для поиска копий, в основном, работают по принципу сравнивания размеров файлов. И, так как вероятность совпадения количества байтов у разных фото практически равна нулю, одинаковые значения считаются признаком дубликата.
Иногда алгоритм предусматривает проверку имён – тоже важный параметр для поиска, тем более что одинаковые данные в большинстве случаев совпадают и по названию.
Преимуществами программ являются возможность найти с их помощью файлы любого типа и сравнительно высокая скорость работы. Недостаток – меньшая точность обнаружения. Так, например, ни одна из таких утилит не посчитает дубликатом одну и ту же фотографию, сохранённую с различным разрешением.
1. DupKiller
Приложение, обеспечивающее поиск файлов практически с любым расширением, можно бесплатно скачать на официальном сайте его производителя.
Среди отличий программы – интерфейс на русском языке, быстрая работа и большое количество настроек.
С помощью DupKiller можно сравнивать файлы и по размеру, и по дате, и по содержимому (последняя возможность поддерживается только для определённых типов).
Рис. 1. Окно программы DupKiller.
2. Duplicate Finder
Приложение Duplicate Finder позволяет не только искать дубликаты файлов с разными расширениями, но и проводить их сортировку.
Для удобства пользователей настройки утилиты позволяют проводить поиск и по размерам, и по контрольным суммам, и по названию.
Кроме того, с её помощью можно удалять пустые папки и «нулевые» файлы. А среди недостатков можно назвать разве что отсутствие поддержки русского языка.
Рис. 2. Результат работы приложения Duplicate Finder.
3. Glary Utilities
Программа представляет собой не одну утилиту, а сразу несколько – для исправления реестра, для очистки диска и даже для управления безопасностью.
Одно из приложений в наборе даёт возможность искать дубликаты файлов. Среди преимуществ утилиты – русский интерфейс.
К минусам можно отнести определённое замедление работы компьютера при использовании приложения.
Рис. 3. Утилита поиска дубликатов в составе пакета Glary Utilities.
Как повысить ФПС в играх: все возможные способы 2017 года
4. CCleaner
Главной задачей многофункциональной программы CCleaner является очистка жёсткого диска компьютера (а также планшета и смартфона, так как у приложения есть версии и для Android). А среди её преимуществ можно отметить:
- простоту настройки;
- установку нескольких критериев поиска;
- возможность игнорировать некоторые файлы (с определённым размером или датой создания, а также системные или скрытые).
Важно: При обнаружении файлов с нулевым размером их не обязательно удалять. Иногда это может быть информация, созданная в другой операционной системе (например, Linux)
Удаление повторяющихся строк
Задача: Есть текстовый список разбитый по строкам. В списке присутствуют некоторые дубли строк. Необходимо удалить дубликаты строк из списка.
Сделать операцию по удалению дублей можно несколькими способами, предварительно вставив список в программу в которой будем работать.
Удалить дубликаты в Microsoft Excel
Выделяем список (столбец) ➤ переходим во вкладку Date (Данные), нажимаем команду Remove Duplicates (Удалить дубликаты) ➤ в открывшемся диалоговом окне «Remove Duplicates» (Удалить дубликаты) снимаем флажок My data has headers (Мои данные содержат заголовки) ➤ нажимаем OK. Все повторяющиеся строки будут удалены, кроме первой (оригинала).
Фильтровать дубликаты в LibreOffice
Выделяем нужные ячейки (столбец целиком) ➤ Открываем меню Date (Данные) ➤ «Ещё фильтры» ➤ «Стандартный фильтр…» ➤ В открывшемся диалоговом окне в поле «Имя поля» выбираем необходимый столбец ➤ В поле «Условие» устанавливаем знак равно «=» ➤ В поле «Значение» указываем «Не пусто» ➤ Внизу в разделе «Параметры» обязательно отмечаем флажок «Без повторений» ➤ Жмем OK. В столбце останутся только единичные экземпляры и можно их скопировать.
 Путь к стандартному фильтру в LibreOffice
Путь к стандартному фильтру в LibreOffice
 Окно стандартного фильтра в Libre Office
Окно стандартного фильтра в Libre Office
Google-Таблицы
Google Таблицы не имеют встроенных функций удаления дублей, поэтому можно использовать установить дополнение «Remove Duplicates». Установить это расширение можно бесплатно.
После установки расширения заходим в Гугл-таблицу, выделяем столбец (строки) где нужно почистить от дублей ➤ нажимаем в меню «Дополнения» ➤ Remove Duplicates (Удалить дубликаты) ➤ Find duplicates or uniques rows (Найти дубликаты или уникальные) ➤ В открывшемся окне на 1-м шаге нажимаем «Next» ➤ во 2-ом шаге выбираем «Duplicates» и далее ➤ пропускаем 3-й шаг далее ➤ и на 4-ом шаге выбираем, что делать с найденными дублями: перенести (Move), копировать (Copy) в другое место, очистить (Clear) или удалить (Delete). Выбираем «Delete rows within selection» (Удалить выделенные строки). Всё, готово.
 Remove Dublicate шаг 1
Remove Dublicate шаг 1
 Remove Dublicate шаг 4
Remove Dublicate шаг 4
NotePad++
Для удаления ненужных дублей строк в NotePad++ необходимо если не установлен.
 Удаление дублей строк плагином TextFX в NotePad++
Удаление дублей строк плагином TextFX в NotePad++
Удаление повторяющихся строк: Переходим в документ со списком и выделяем (Ctrl+A) ➤ нажимаем в меню TextFX ➤ TextFX Tools ➤ проверяем отмечена ли функция Sort outputs only UNIQUE lines (Сортировать вывод только по УНИКАЛЬНЫМ строкам), ➤ если да, то сразу выбираем Sort lines case insensitive (Сортировка строк без учета регистра).
Удаление дублей онлайн
Для удаления повторяющихся строк (например, это может быть список ключевых слов из KeyCollector, Excel, NotePad и пр.) можно воспользоваться онлайн инструментом удаления дубликатов «Сервис удаления дублей строк».
Удаление
Поиск дублей может занять до нескольких часов, в зависимости от того, какая папка или диск для этого выбраны. После завершения поиска CCleaner предложит файлы на удаление, они будут поделены на подразделы.
Перед удалением стоит проверить предложенные файлы, это можно сделать непосредственно в программе, кликнув правой кнопкой мыши на него и выбрать команду «Открыть файл», там же есть еще несколько команд:
- «Выделить все» – отмечает все найденные дубликаты и удаляет их, оставляя только одну, нижнюю копию.
- «Выделить тип» – выделяет файлы одного типа.
- «Снять выделение» – дает возможность исключить один файл из общего списка.
- «Снять с типа» – снимает отметки с однотипных файлов.
- «Исключить, ограничить, выбрать дубликаты» – производит действие только в одной папке, в которой находится файл.
- «Сохранить отчет» – сохранение отчета в текстовом документе.
- «Открыть папку» – открывает папку, в которой расположен файл.
После того как данные проверены, можно выделить файлы на удаление, поставив отметку, и удалить отмеченные.
Важно! Программа не даст удалить все копии файла, один из них должен остаться. Если вы решили, что такой файл не нужен, удалять его придется не через программу, а в папке, в которой он расположен.
Поиск и удаление дублей на CMS WordPress
На WordPress создаваемый пост попадает на сайт как статья, и дублируется в архивах категории, архивах тегов, по дате, по автору. Чтобы избавиться от дублей на WordPress, разумно закрыть от индексации все архивы или, по крайней мере, архивы по дате и по автору.
Использовать для этих целей можно файл robots.txt с оговорками сделанными выше. Или лучше, установить SEO плагин, который, поможет в борьбе с дублями. Рекомендую плагины:
- Yast SEO (https://ru.wordpress.org/plugins/wordpress-seo/)
- All in One SEO Pack (https://ru.wordpress.org/plugins/all-in-one-seo-pack/)
В плагинах есть настройки закрывающие архивы от индексации и масса других SEO настроек, который избавят от рутинной работы по оптимизации WordPress.
Причины возникновения дублей на сайте
Ошибка контент-менеджера
Самая банальная ситуация —когда контент добавили на сайт дважды, то есть созданы одинаковые страницы. К счастью, таких ситуаций легко можно избежать.
Если у вас сайт с преимущественно текстовым наполнением, вам стоит вести контент-план, с помощью которого вы сможете следить за своими публикациями. В любом случае необходимо периодически делать ревизию контента и следить за посадочными страницами, чтобы избежать проблем с каннибализацией и дублями.
Если контент добавлен и проиндексирован, необходимо определить основную страницу и оставить только ее. Для этого воспользуйтесь инструкциями ниже в секции «Выбор основной версии страницы».
URL с параметрами
Чаще всего именно параметры становятся причиной дублирования контента и траты краулингового бюджета на страницы, не представляющие ценности.
Параметры и дубли страниц могут появляться при:
Классическим решением является использование тега canonical. В таком случае все страницы с параметрами указывают на страницу без параметров как на каноническую. Например: https://seranking.ru/?sort=desc содержит <link rel=»canonical» href=»https://seranking.ru/»/>.
Второй классический вариант решения проблемы — использование метатега robots либо X-Robots-Tag с директивой noindex для предотвращения индексации страниц.
В случае страниц с параметрами лично мне больше нравится решение с canonical
Но важно помнить, что canonical является для поисковиков только рекомендацией. . Для решения проблем фильтрации я рекомендую заменять теги на для тех фильтров, которые заведомо создают страницы-дубли или страницы, которые вы не планируете индексировать
Это более сложное решение, которое экономит краулинговый бюджет, но требует постановки задачи разработчику.
Для решения проблем фильтрации я рекомендую заменять теги <a> на <span> для тех фильтров, которые заведомо создают страницы-дубли или страницы, которые вы не планируете индексировать. Это более сложное решение, которое экономит краулинговый бюджет, но требует постановки задачи разработчику.
Однотипные товары с различными вариантами продукта
Я приверженец практики, когда для практически одинаковых товаров — например, футболок разных цветов — используют одну и ту же карточку товара, а нужный вам вариант можно выбрать при заказе. Таким образом минимизируется число дублей — карточек товара с одинаковым продуктом, а пользователь всегда попадает именно на тот товар, который он ищет. Такое решение также позволяет сэкономить краулинговый бюджет и избежать каннибализации.
Региональные версии сайтов
Для сайтов услуг проблема решается проще. Если вы создаете страницы под разные города, пишите уникальный локальный контент для конкретной локации.
Использование hreflang помогает решить проблему с частичными дублями, но использовать этот инструмент нужно аккуратно и обязательно отслеживать ситуацию.
Последняя ситуация, которая встречается реже, — использование региональных доменов с одинаковым контентом, т.е. когда каждый регион\область\штат имеет свой сайт на отдельном домене, но при этом используют одинаковый либо похожий контент. В таком случае стоит, опять-таки, уникализировать контент с учетом особенностей каждой локации и правильно настроить теги hreflang.
Доступность товара в разных категориях
https://site.com/t-shirt/nike/t-shirt-best.html и https://site.com/t-shirt/red/t-shirt-best.html
Эту проблему можно решить, исправив логику работы CMS, чтобы для товаров в разных категориях всегда использовался один URL. На мой взгляд, это оптимальное решение проблемы. Также можно использовать тег canonical.
Технические проблемы
Одна из самых популярных проблем дублирования — техническая. Особенно часто проблема встречается в самописных или малопопулярных CMS, но грешат этим и более именитые системы. Поэтому SEO-специалист всегда должен быть на чеку и контролировать параметры, которые приводят к дублированию: настроено ли главное зеркало, обрабатываются ли завершающие слеши и т.д. Полный список возможных технических проблем, из-за которых на сайте появляются полные дубли, я приводил выше.
Обработка найденных дубликатов
Отлично, мы нашли записи в первом столбце, которые также присутствуют во втором столбце. Теперь нам нужно что-то с ними делать. Просматривать все повторяющиеся записи в таблице вручную довольно неэффективно и занимает слишком много времени. Существуют пути получше.
Показать только повторяющиеся строки в столбце А
Если Ваши столбцы не имеют заголовков, то их необходимо добавить. Для этого поместите курсор на число, обозначающее первую строку, при этом он превратится в чёрную стрелку, как показано на рисунке ниже:
Кликните правой кнопкой мыши и в контекстном меню выберите Insert (Вставить):
Дайте названия столбцам, например, «Name» и «Duplicate?» Затем откройте вкладку Data (Данные) и нажмите Filter (Фильтр):
После этого нажмите меленькую серую стрелку рядом с «Duplicate?«, чтобы раскрыть меню фильтра; снимите галочки со всех элементов этого списка, кроме Duplicate, и нажмите ОК.
Вот и всё, теперь Вы видите только те элементы столбца А, которые дублируются в столбце В. В нашей учебной таблице таких ячеек всего две, но, как Вы понимаете, на практике их встретится намного больше.
Чтобы снова отобразить все строки столбца А, кликните символ фильтра в столбце В, который теперь выглядит как воронка с маленькой стрелочкой и выберите Select all (Выделить все). Либо Вы можете сделать то же самое через Ленту, нажав Data (Данные) > Select & Filter (Сортировка и фильтр) > Clear (Очистить), как показано на снимке экрана ниже:
Изменение цвета или выделение найденных дубликатов
Если пометки «Duplicate» не достаточно для Ваших целей, и Вы хотите отметить повторяющиеся ячейки другим цветом шрифта, заливки или каким-либо другим способом…
В этом случае отфильтруйте дубликаты, как показано выше, выделите все отфильтрованные ячейки и нажмите Ctrl+1, чтобы открыть диалоговое окно Format Cells (Формат ячеек). В качестве примера, давайте изменим цвет заливки ячеек в строках с дубликатами на ярко-жёлтый. Конечно, Вы можете изменить цвет заливки при помощи инструмента Fill (Цвет заливки) на вкладке Home (Главная), но преимущество диалогового окна Format Cells (Формат ячеек) в том, что можно настроить одновременно все параметры форматирования.
Теперь Вы точно не пропустите ни одной ячейки с дубликатами:
Удаление повторяющихся значений из первого столбца
Отфильтруйте таблицу так, чтобы показаны были только ячейки с повторяющимися значениями, и выделите эти ячейки.
Если 2 столбца, которые Вы сравниваете, находятся на разных листах, то есть в разных таблицах, кликните правой кнопкой мыши выделенный диапазон и в контекстном меню выберите Delete Row (Удалить строку):
Нажмите ОК, когда Excel попросит Вас подтвердить, что Вы действительно хотите удалить всю строку листа и после этого очистите фильтр. Как видите, остались только строки с уникальными значениями:
Если 2 столбца расположены на одном листе, вплотную друг другу (смежные) или не вплотную друг к другу (не смежные), то процесс удаления дубликатов будет чуть сложнее. Мы не можем удалить всю строку с повторяющимися значениями, поскольку так мы удалим ячейки и из второго столбца тоже. Итак, чтобы оставить только уникальные записи в столбце А, сделайте следующее:
- Отфильтруйте таблицу так, чтобы отображались только дублирующиеся значения, и выделите эти ячейки. Кликните по ним правой кнопкой мыши и в контекстном меню выберите Clear contents (Очистить содержимое).
- Очистите фильтр.
- Выделите все ячейки в столбце А, начиная с ячейки А1 вплоть до самой нижней, содержащей данные.
- Откройте вкладку Data (Данные) и нажмите Sort A to Z (Сортировка от А до Я). В открывшемся диалоговом окне выберите пункт Continue with the current selection (Сортировать в пределах указанного выделения) и нажмите кнопку Sort (Сортировка):
- Удалите столбец с формулой, он Вам больше не понадобится, с этого момента у Вас остались только уникальные значения.
- Вот и всё, теперь столбец А содержит только уникальные данные, которых нет в столбце В:
Как видите, удалить дубликаты из двух столбцов в Excel при помощи формул – это не так уж сложно.
Удаление одинаковых значений таблицы в Excel
Работая в самом популярном редакторе таблиц Microsoft Excel, пожалуй, каждый пользователь сталкивался с проблемой удаления повторяющихся значений. К счастью, в самом редакторе Excel предусмотрены средства и инструменты, позволяющие наиболее легко разобраться с подобной неприятностью. В этой статье подробно рассмотрим самые простые и эффективные пути решения этой задачи. Итак, давайте разбираться. Поехали!
Microsoft Excel – это одна из самых популярных программ для работы с числами и таблицами
К примеру, у вас имеется таблица с данными, в которой есть несколько совпадений. Чтобы исправить это, существует два способа:
- Кнопка «Удалить дубликаты»;
- С использованием расширенного фильтра.
Ниже разберём каждый из них более подробно.
Первый способ подойдёт для версии Microsoft Excel 2007 и более новых. Здесь разработчики предельно упростили жизнь пользователей, добавив специальный инструмент программы непосредственно для решения этой неприятности. В панели инструментов вы сможете обнаружить пункт «Удалить дубликаты», который находится в блоке «Работа с данными». Работает это так:
- Сначала перейдите на нужную страницу.
- Затем нажмите «Удалить дубликаты».
- Далее, перед вами откроется окно, в котором необходимо отметить столбцы, где имеются совпадающие значения.
После этого Эксель удалит одинаковые элементы в тех столбцах, которые вы отметили.
Преимущество такого подхода в том, что можно избавиться от повторяющихся значений всего за пару кликов, за несколько секунд. Но есть и недостаток — в том случае, если приходится работать с очень большой таблицей, то все одинаковые элементы можно банально не найти. Поэтому перейдём к следующему способу.
Второй подход заключается в использовании расширенного фильтра и работает как на новых версиях Microsoft Excel, так и на старых, включая 2003. Тут придётся понажимать несколько больше, однако, такой подход в разы более эффективен. Итак, сначала нужно открыть таблицу, затем перейдите во вкладку «Данные», в блоке «Сортировка и фильтр» выберите пункт «Дополнительно». Перед вами откроется окно, в котором нужно будет задать диапазон (только в том случае, если у вас есть разрывы, в противном случае ничего задавать не нужно) и поставить птичку на пункте «Только уникальные записи». Если вы хотите просто скрыть дубликаты, чтобы иметь возможность ещё поработать с ними в дальнейшем, то выберите фильтрование списка на месте, если же вы укажете «скопировать результат в другое место», то повторяющиеся элементы будут удалены. После нажатия «ОК» таблица будет отфильтрована программой в соответствии с выбранными вами параметрами. Теперь выделите цветом уникальные элементы и нажмите «Очистить». В результате вы увидите все дубликаты, так как они не будут отмечены цветом. Воспользовавшись автофильтром, можно будет получить полный перечень неуникальных значений.
Использование набора ()
Простой и быстрый подход для удаления дубликатов элементов из списка в Python будет использовать встроенный Python Способ преобразования элементов списка в уникальный набор, следующий, который мы можем преобразовать его в список, теперь удаляемую все его дубликаты элементов.
first_list = # Convert to a set first set_list = set(first_list) # Now convert the set into a List print(list(set_list)) second_list = # Does the same as above, in a single line print(list(set(second_list)))
Выход
Проблема с таким подходом состоит в том, что оригинальный порядок списка не поддерживается как с случаем второго списка, поскольку мы создаем новый список из неупорядоченного набора. Поэтому, если вы хотите по-прежнему сохранить относительную порядок, вы должны избежать этого метода.
Результаты
CCleaner выдаст результат поиска и это будет множество файлов, пугаться их количества не стоит
Так же как и ругать разработчиков, что нет функции «Удалить все», это убережет пользователя от неосторожного удаления нужных файлов и сподвигнет просмотреть каждый из них
После того как очистите память своего компьютера, удалив все повторы, он отблагодарит вас быстрым доступом и загрузкой всех систем.
Как понять, какие можно удалять, а что лучше оставить?
Лучше удалять только знакомые файлы, которые были созданы непосредственно вами:
- фото;
- видео;
- документы;
- рефераты;
- листы Excel и Word.
Оставляем нетронутыми данные с расширением dll, dlc или exe. Они могут относиться к системным библиотекам и исполнительным файлам, их удаление нарушит работу многих программ.
Внимание! Не стоит забывать, что программа – это только инструмент для поиска ненужных файлов, а пользователь уже решает, насколько они важны.
CCleaner – очень простой, удобный в использовании и, главное, бесплатный инструмент, который подойдет для быстрой и качественной чистки системы и на любом устройстве, будь это хоть сотовый телефон, компьютер или планшет.
Интерфейс программы достаточно удобный и полностью на русском языке, поэтому разобраться с ним сможет даже начинающий пользователь. Эта утилита не только удалит лишние данные, но и почистит устройство быстро и безопасно.
Функция удаления дубликатов
Проще всего избавляться от повторов, доверив удаление автоматической встроенной в программу функции. Этот способ удаления повторяющихся строк в Excel самый быстрый и простой. Хотя не исключена вероятность того, что программа удалит что-то лишнее — или, наоборот, пропустит «неполные» повторения.
Использовать такую методику стоит, если пользователю нужно быстро убрать дублирующиеся данные — или если таких дубликатов слишком много.
Порядок действия для устранения повторов в таблице следующий:
- Выделить область таблицы и открыть вкладку «Данные».
- Перейти к группе команд «Работа с данными».
- Найти иконку функции удаления дубликатов, которая выглядит как два расположенных рядом цветных столбца.
- Кликнуть по ней и, если в столбцах есть заголовки, поставить галочку напротив соответствующего пункта в открывшемся окне.
- Нажать «ОК» и получить в результате файл без дубликатов.
С помощью такой методики можно удалить те строки, которые полностью совпадают друг с другом. Обычно это происходит при копировании информации из 2-3 и более файлов в одну таблицу. Но иногда возникает необходимость удалить дубли в Экселе, где информация совпадает только частично. Это может быть, например, каталог товаров, где есть одни и те же наименования с отличающимися ценами.
Простое удаление не позволит устранить повторы, если стоимость будет другой. Избежать ошибки можно, выбрав при настройке удаления дубликатов только те столбцы, которые будут сравниваться. Например, «Название» и «Марка» — но без «Цены» и «Количества».
Метод 3: использование фильтра
Теперь обратим внимание на специальный метод, который позволяет не удалить дубликаты из таблицы, а просто скрыть их. По факту этот метод позволяет форматировать таблицу таким образом, чтобы при дальнейшей работе с таблицей вам ничто не мешало и была возможность визуально получить только актуальную и полезную информацию
Чтобы реализовать его, вам достаточно будет выполнить следующие действия:
- Первым делом следует выделить полностью таблицу, в которой вы собираетесь провести манипуляции по удалению дубликатов.
- Теперь перейдите в раздел «Данные» и сразу перейдите в подраздел «Фильтр».
Выделяем диапазон таблицы и используем фильтр
- Явным признаком того, что фильтр был активирован, является наличие в шапке таблицы специальных стрелок, после этого вам будет достаточно воспользоваться ими и указать информацию касательно дубликатов (к примеру, слово или обозначение в поиске).
Таким образом можно сразу отфильтровать все дубликаты и произвести дополнительные манипуляции с ними.
Расширенный фильтр для поиска дубликатов в Excel
Имеется еще дополнительный способ использования фильтров в программе Excel, для этого вам понадобится:
- Выполнить все действия прошлого метода.
- В окне инструментария воспользоваться значком «Дополнительно», который находится около того самого фильтра.
Используем расширенный фильтр
После использования данного значка вам достаточно будет обратить внимание на окно дополнительных настроек. Этот расширенный инструментарий позволит ознакомиться с первоначальной информацией:
поначалу следует проверить указанный диапазон таблицы, чтобы он совпадал с тем, что вы отмечали;
обязательно отметьте пункт «Только уникальные записи»;
как только все будет готово, остается лишь нажать на кнопку «ОК».. Проверяем и подтверждаем установки фильтра
Проверяем и подтверждаем установки фильтра
- Как только все рекомендации будут выполнены, вам останется лишь взглянуть на таблицу и убедиться в том, что дубликаты больше не отображаются. Это будет сразу видно, если взглянуть на информацию снизу слева, где отражается количество строк, отображаемое на экране.
Проверяем дополнительную информацию после фильтрации
Поиск дубликатов при помощи встроенных фильтров Excel
Организовав данные в виде списка, Вы можете применять к ним различные фильтры. В зависимости от набора данных, который у Вас есть, Вы можете отфильтровать список по одному или нескольким столбцам. Поскольку я использую Office 2010, то мне достаточно выделить верхнюю строку, в которой находятся заголовки, затем перейти на вкладку Data (Данные) и нажать команду Filter (Фильтр). Возле каждого из заголовков появятся направленные вниз треугольные стрелки (иконки выпадающих меню), как на рисунке ниже.
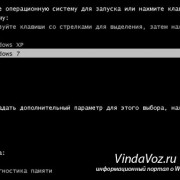
Если нажать одну из этих стрелок, откроется выпадающее меню фильтра, которое содержит всю информацию по данному столбцу. Выберите любой элемент из этого списка, и Excel отобразит данные в соответствии с Вашим выбором. Это быстрый способ подвести итог или увидеть объём выбранных данных. Вы можете убрать галочку с пункта Select All (Выделить все), а затем выбрать один или несколько нужных элементов. Excel покажет только те строки, которые содержат выбранные Вами пункты. Так гораздо проще найти дубликаты, если они есть.
После настройки фильтра Вы можете удалить дубликаты строк, подвести промежуточные итоги или дополнительно отфильтровать данные по другому столбцу. Вы можете редактировать данные в таблице так, как Вам нужно. На примере ниже у меня выбраны элементы XP и XP Pro.
В результате работы фильтра, Excel отображает только те строки, в которых содержатся выбранные мной элементы (т.е. людей на чьём компьютере установлены XP и XP Pro). Можно выбрать любую другую комбинацию данных, а если нужно, то даже настроить фильтры сразу в нескольких столбцах.
Расширенный фильтр для поиска дубликатов в Excel
На вкладке Data (Данные) справа от команды Filter (Фильтр) есть кнопка для настроек фильтра – Advanced (Дополнительно). Этим инструментом пользоваться чуть сложнее, и его нужно немного настроить, прежде чем использовать. Ваши данные должны быть организованы так, как было описано ранее, т.е. как база данных.
Перед тем как использовать расширенный фильтр, Вы должны настроить для него критерий. Посмотрите на рисунок ниже, на нем виден список с данными, а справа в столбце L указан критерий. Я записал заголовок столбца и критерий под одним заголовком. На рисунке представлена таблица футбольных матчей. Требуется, чтобы она показывала только домашние встречи. Именно поэтому я скопировал заголовок столбца, в котором хочу выполнить фильтрацию, а ниже поместил критерий (H), который необходимо использовать.
Теперь, когда критерий настроен, выделяем любую ячейку наших данных и нажимаем команду Advanced (Дополнительно). Excel выберет весь список с данными и откроет вот такое диалоговое окно:
Как видите, Excel выделил всю таблицу и ждёт, когда мы укажем диапазон с критерием. Выберите в диалоговом окне поле Criteria Range (Диапазон условий), затем выделите мышью ячейки L1 и L2 (либо те, в которых находится Ваш критерий) и нажмите ОК. Таблица отобразит только те строки, где в столбце Home / Visitor стоит значение H, а остальные скроет. Таким образом, мы нашли дубликаты данных (по одному столбцу), показав только домашние встречи:
Это достаточно простой путь для нахождения дубликатов, который может помочь сохранить время и получить необходимую информацию достаточно быстро. Нужно помнить, что критерий должен быть размещён в ячейке отдельно от списка данных, чтобы Вы могли найти его и использовать. Вы можете изменить фильтр, изменив критерий (у меня он находится в ячейке L2). Кроме этого, Вы можете отключить фильтр, нажав кнопку Clear (Очистить) на вкладке Data (Данные) в группе Sort & Filter (Сортировка и фильтр).