7 правил rfc 4180
Содержание:
- Диалекты и параметры форматирования¶
- Reader Objects¶
- Использование DictReader
- Методы для группировки данных по полю,полям в Таблице Значений на примере универсального метода списания по партиям, а также отбора строк в ТЗ по произвольному условию. Для 8.x и 7.7 Промо
- Инверсия управления спешит на помощь
- Открыть файл VCF на ПК
- Процедура открытия
- Важная информация о редактировании файлов csv
- Как преобразовать файл Excel в CSV
- Чтение с помощью Pandas
- Examples¶
- Файлы CSV
- Проверяем кодировку CSV файла
- Как структурированы csv файлы
- Заключение
Диалекты и параметры форматирования¶
Для упрощения задания формата входных и выходных записей, конкретные параметры
форматирования группируются в диалекты. Диалект — это подкласс
класса, имеющий набор специфических методов и единственный
метод. Создавая объекты или , программист может
определить строку или подкласс класса как параметр
диалекта. В дополнение, или вместо, параметра dialect, программист может
также определить отдельные параметры форматирования, у которых есть те же имена
как атрибуты, определенный ниже для класса .
Диалекты поддерживают следующие атрибуты:
-
Односимвольная строка, используемая для отделения полей. По
умолчанию .
-
Управляет тем, как сущности quotechar, появляющиеся внутри поля, должены
самостоятельно закавычиваться. Когда , символ удваивается. Когда
, escapechar — используется как префикс к quotechar. По
умолчанию он .При выводе, если doublequote и не установлен escapechar,
поднимается , если quotechar найден в поле.
-
Односимвольная строка используемая writer, чтобы экранировать delimiter,
если quoting установлен в и quotechar, если doublequote —
. При чтении escapechar удаляет какое-либо особое значение со
следующего символа. По умолчанию используется значение , которое
отключает экранирование.
-
Используемая строка используемая для завершения строки, произведенная . По
умолчанию используется значение .Примечание
В жёсто закодированы опознавательные символы или
как конец строки и игнорирует lineterminator. Это поведение может измениться в
будущем.
-
Одиносимвольная строка используемая для заковычивания полей, содержащих
специальные символы, такие как delimiter или quotechar, или которые содержат
символы новой строки. По умолчанию используется значение .
-
Контролирует, когда кавычки должны генерироваться writer и распознаваться
reader. Он может принимать любые константы (см. раздел
) и по умолчанию имеет значение .
-
При , пробелы непосредственно следующие за delimiter, игнорируются.
Значение по умолчанию — .
Reader Objects¶
Reader objects ( instances and objects returned by the
function) have the following public methods:
- ()
-
Return the next row of the reader’s iterable object as a list (if the object
was returned from ) or a dict (if it is a
instance), parsed according to the current . Usually you
should call this as .
Reader objects have the following public attributes:
-
A read-only description of the dialect in use by the parser.
-
The number of lines read from the source iterator. This is not the same as the
number of records returned, as records can span multiple lines.
DictReader objects have the following public attribute:
Использование DictReader
Эта функция используется для вывода данных из текстового файла в виде словаря.
У нас есть файл sample7.txt со следующими данными об учениках.
Примечание. Не обязательно сохранять файл с расширением .csv, можно и в других форматах. Главное, чтобы в самом файле использовался простой текст и данные оставались в первозданном виде.
Теперь воспользуемся приведенным ниже кодом, чтобы прочитать данные и вывести их в формате словаря. Вся методика одинакова, только вместо используется .
csv_file = csv.DictReader(file)
Во время выполнения можно видеть, что данные печатаются в виде словаря. Данная функция преобразует каждую строку в словарь.
Методы для группировки данных по полю,полям в Таблице Значений на примере универсального метода списания по партиям, а также отбора строк в ТЗ по произвольному условию. Для 8.x и 7.7 Промо
Я очень часто использую группировку данных по полю и полям, как в восьмерке, так и в семерке. Это аналог запроса Итоги, но там строится дерево, а в большинстве случаев нужны «плоские данные». Да и делать запрос в большинстве случаев более накладный процесс, чем работа с ТЗ.
Все достоинства такого подхода приведены на примере метода универсального списания по париям, а так же отбора строк в ТЗ по произвольному условию.
Для 7.7 еще отчеты сравнения двух ТЗ. Работая с различными базами для упрощения сравнения номенклатуры, или как аналог джойнов(join), сделал сравнение двух таблиц значений по нескольким полям. Пока группировки полей должны быть уникальны.
Часто приходится искать дубли, для универсального поиска есть ДублиВТзПоПолю и пример в Тест.ert.
1 стартмани
Инверсия управления спешит на помощь
Учитывая размытость стандарта CSV, не практично писать универсальное средство разбора для всех случаев. Гораздо разумнее писать средство разбора, подходящее для конкретных потребностей какого-либо приложения. Используя инверсию управления (Inversion of Control), вы можете адаптировать механизм разбора под конкретные требования.
С этой целью я создам интерфейс, определяющий две базовые функции синтаксического разбора: для получения записей и извлечения полей. Я решил сделать интерфейс IParserEngine асинхронным. Это гарантирует, что любое приложение, использующее этот компонент, не перестанет отвечать при разборе CSV-файла даже очень большого размера:
После этого я добавляю в класс CSVParser следующее свойство:
И предлагаю разработчикам выбор: использовать средство разбора по умолчанию или встроить собственное. Чтобы упростить эту задачу, я перегрузил конструктор:
Теперь класс CSVParser предоставляет базовую инфраструктуру, а реальная логика синтаксического анализа содержится в интерфейсе IParserEngine. Для удобства разработчиков я создал DefaultParserEngine, который может обрабатывать большинство CSV-файлов.
Открыть файл VCF на ПК
Если у вас есть файл VCF и вы хотите импортировать его на свой компьютер, используя свой любимый почтовый клиент, следуйте приведенным ниже инструкциям.
Microsoft Outlook (Windows / Mac)
Вы используете Microsoft Outlook в качестве почтового клиента по умолчанию? Тогда знайте, что вы можете импортировать контакты, содержащиеся в файле VCF, непосредственно в адресную книгу программы. Всё, что вам нужно сделать, это нажать кнопку Файл, расположенную в левом верхнем углу, перейти в меню «Открыть и экспортировать» и нажать кнопку Импорт / экспорт.
В открывшемся окне выберите параметр Импорт файла vCard (.vcf), нажмите Далее и выберите файл vcf, из которого необходимо импортировать контакты.
Процедура, которую я только что проиллюстрировал, касается Outlook 2019, но может быть применена с очень небольшими изменениями и в предыдущих версиях программного обеспечения.
Mozilla Thunderbird (Windows / Mac / Linux)
Вы предпочитаете использовать Mozilla Thunderbird для управления своей электронной почтой? Отлично. Даже в этом случае достаточно нескольких щелчков мыши, чтобы открыть файлы VCF и импортировать контакты в адресную книгу.
Всё, что вам нужно сделать, это вызвать адресную книгу, нажав соответствующую кнопку на панели инструментов Thunderbird (вверху слева) и выбрать Инструменты → Импорт из меню, доступного в открывшемся окне.
На этом этапе установите флажок рядом с элементом «Адресные книги», нажмите Далее, выберите запись файла vCard (.vcf) и снова нажмите Далее, чтобы выбрать файл VCF, из которого необходимо импортировать имена и адреса электронной почты.
Apple Mail (Mac)
Если двойной щелчок не открывает автоматически приложение «Контакты» на Mac, запустите его вручную (найдите его значок на первом экране панели запуска), выберите пункт «Файл» → «Импорт» в меню слева вверху и выберите файл VCF с контактами для импорта. Вас могут попросить подтвердить данные некоторых контактов для завершения операции.
Бесплатный конвертер VCF файлов в CSV
Если вы хотите просмотреть содержимое CSV-файла, импортировать его в адресную книгу на вашем компьютере или почтовом клиенте, вы можете положиться на Free VCF file to CSV Converter. Это макрос для Microsoft Excel, который позволяет просматривать содержимое VCF-файлов в виде электронной таблицы и экспортировать их в форматы, подобные CSV (что принято большинством почтовых клиентов и онлайн-служб электронной почты).
Чтобы использовать макрос, загрузите его на свой компьютер, подключившись к странице SourceForge, на которой он находится, и нажав зеленую кнопку Загрузить. После завершения загрузки откройте файл VCF Import v3.xlsm, нажмите кнопку Включить содержимое, чтобы авторизовать выполнение сценариев в документе, и выберите файл VCF для отображения. Подождите несколько секунд, и все данные в файле (имена, адреса электронной почты, номера телефонов, адреса и т.д.) должны появиться в Excel. Вас могут спросить, хотите ли вы удалить пустые строки.
Чтобы экспортировать документ в виде файла CSV или листа Excel, перейдите в меню «Файл» → «Сохранить как» и выберите тип файла, который вы предпочитаете, в раскрывающемся меню «Сохранить как»
Процедура открытия
Не так много онлайн-сервисов предлагают возможность не только конвертации, но и удаленного просмотра содержимого файлов CSV. Тем не менее, такие ресурсы существуют. Об алгоритме работы с некоторыми из них мы и поговорим в этой статье.
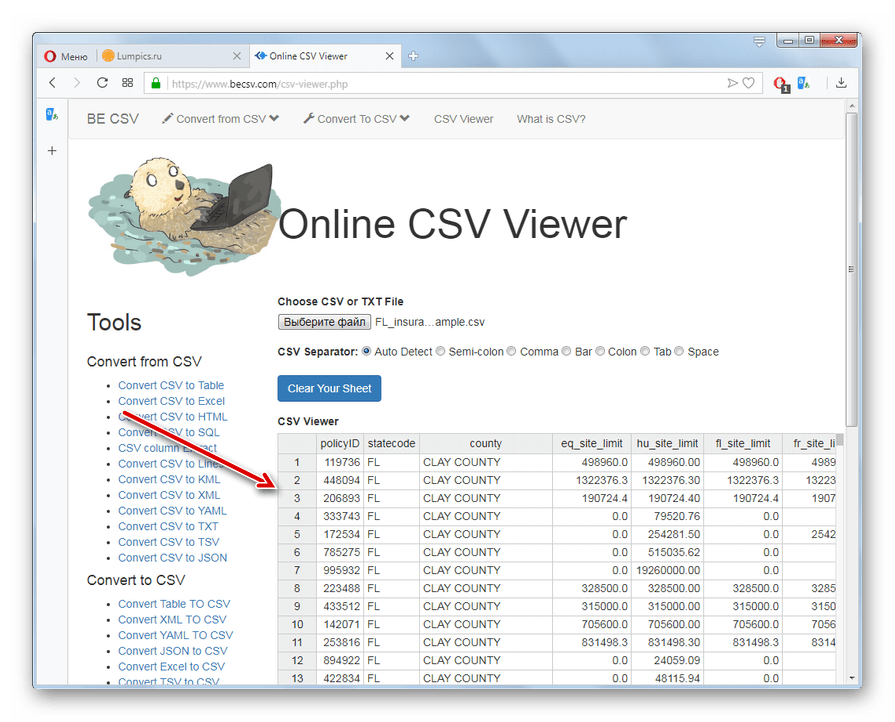
Способ 1: BeCSV
Одним из самых популярных сервисов, который специализируется на работе с CSV, является BeCSV. На нем можно не только просматривать указанный тип файлов, но и преобразовывать в данный формат объекты с другими расширениями и наоборот.
Способ 2: ConvertCSV
Ещё одним онлайн-ресурсом, на котором можно производить различные манипуляции с объектами формата CSV, в том числе и просмотр их содержимого, является популярный сервис ConvertCSV.
- Перейдите на главную страницу ConvertCSV по представленной выше ссылке. Далее щелкните по пункту «CSV Viewer and Editor».
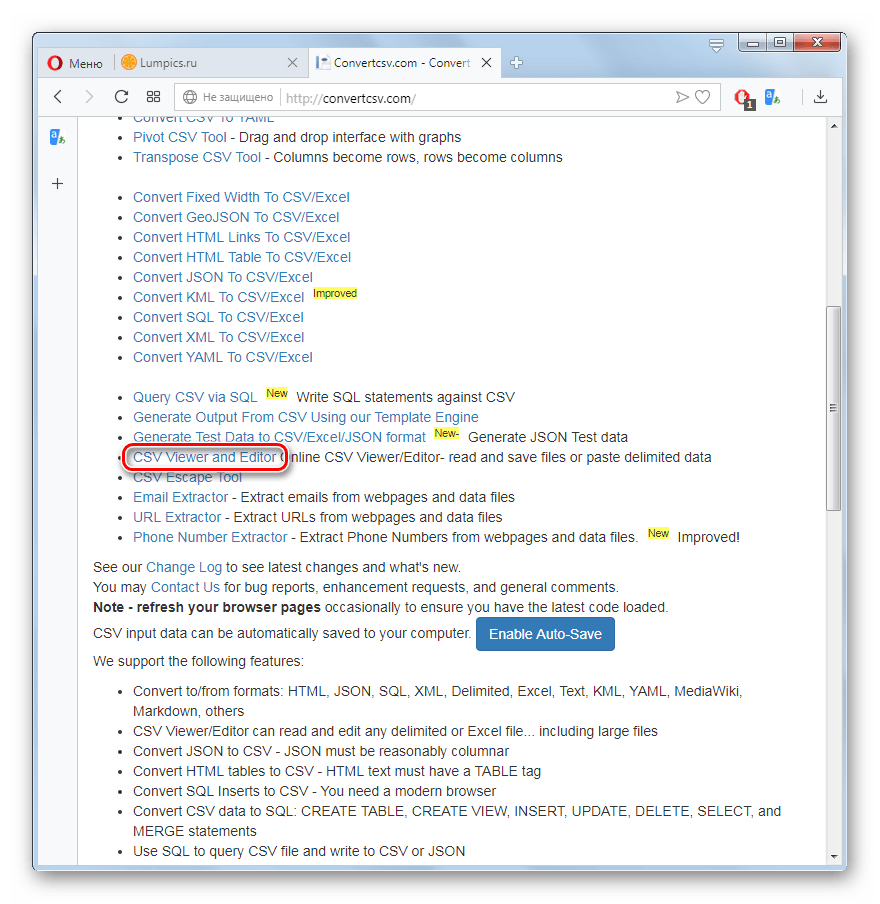
Откроется раздел, в котором можно онлайн не только просматривать, но и редактировать CSV. В отличие от предыдущего метода, данный сервис в блоке «Select your input» предлагает сразу 3 варианта добавления объекта:
- Выбор файла с компьютера или с подключенного к ПК дискового носителя;
- Добавление ссылки на размещенный в интернете CSV;
- Ручная вставка данных.
Так как задачей, которая ставится в этой статье, является просмотр уже существующего файла, в данном случае подойдет первый и второй варианты, в зависимости от того, где объект размещен: на жестком диске ПК или в сети.
При добавлении размещенного на компьютере CSV щелкните напротив опции «Choose a CSV/Excel file» по кнопке «Выберите файл».
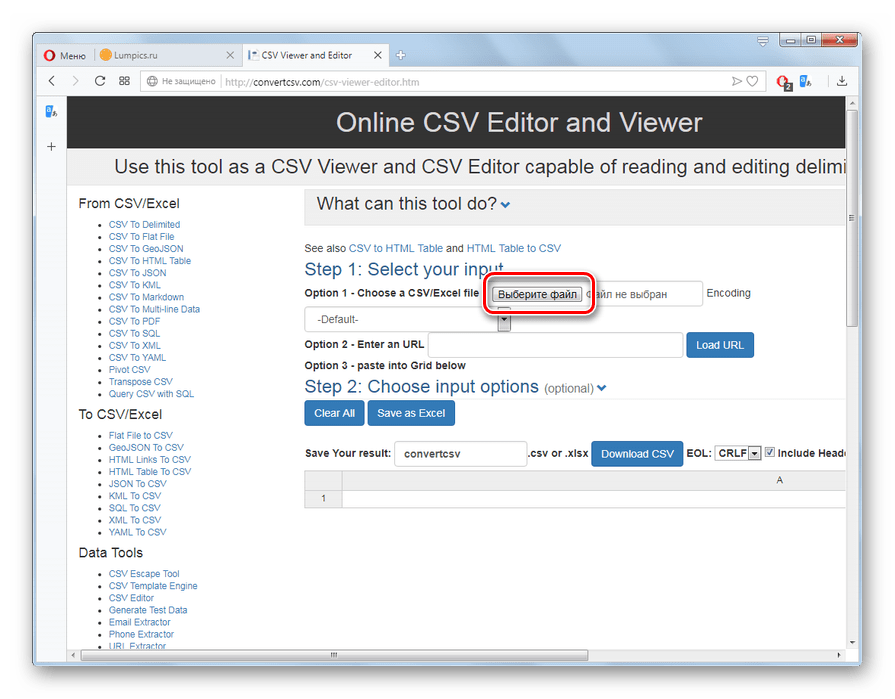
Далее, как и при использовании предыдущего сервиса, в открывшемся окне выбора файла переместитесь в директорию дискового носителя, которая содержит в себе CSV, выделите этот объект и нажмите «Открыть».
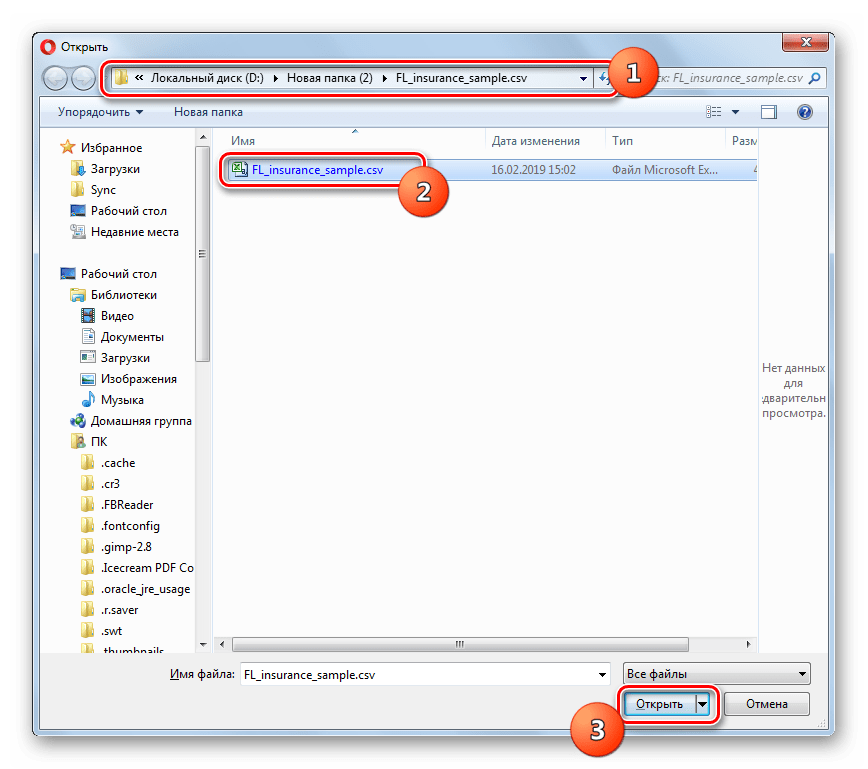
После того как вы щелкнули по вышеуказанной кнопке, объект будет загружен на сайт и его содержимое отобразится в табличном виде прямо на странице.
Если же вы желаете просмотреть содержимое файла, который размещен во всемирной паутине, в этом случае напротив опции «Enter an URL» введите полный его адрес и щелкните по кнопке «Load URL». Результат будет представлен в табличном виде, как и при загрузке CSV с компьютера.
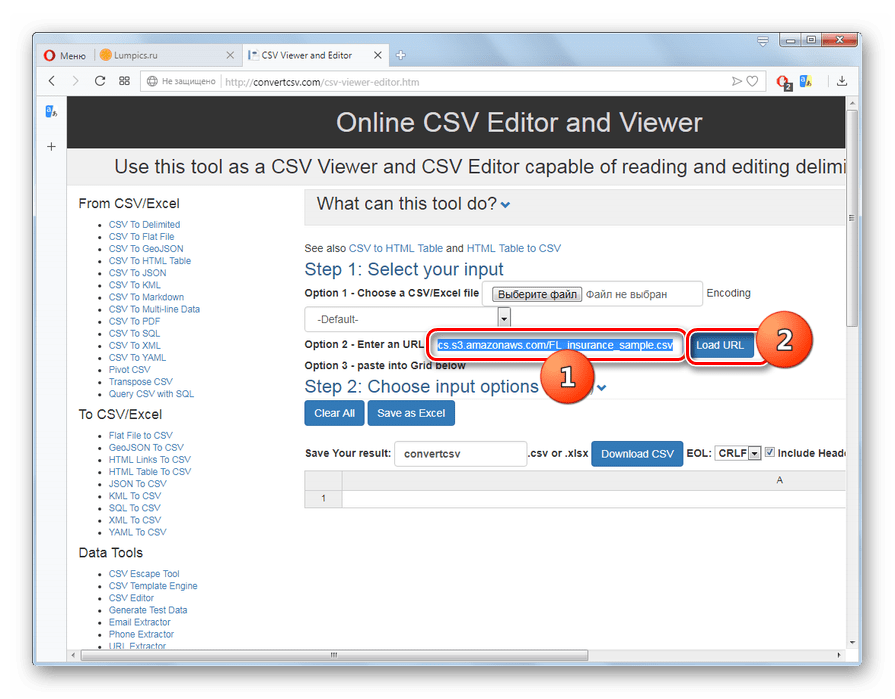
Из двух рассмотренных веб-сервисов ConvertCSV является несколько более функциональным, так как позволяет производить не только просмотр, но и редактирование CSV, а также выполнять загрузку исходника из интернета. Но для простого просмотра содержимого объекта возможностей сайта BeCSV тоже будет вполне достаточно.
Опишите, что у вас не получилось.
Наши специалисты постараются ответить максимально быстро.
Важная информация о редактировании файлов csv
Вся система выходит из строя, если в строке стоит пропущенная или лишняя запятая. Каждое значение после этого отсутствующего или лишнего поля данных будет введено в неправильный столбец
В худшем случае база данных может быть повреждена настолько серьезно, что потребуется вернуться к версии резервной копии, что приведет к потере самых последних изменений данных и проблем для администратора, поэтому важно поддерживать файловую структуру. Столбцы в вашем CSV-файле могут появляться в любом порядке, если эта последовательность сохраняется
Другими словами, порядок, в котором заголовки столбцов появляются в первой строке, должен повторяться в последующих строках данных, чтобы данные в каждом поле можно было сопоставить с правильным столбцом. У вас есть возможность опустить любые столбцы, в которых не хотите добавлять или редактировать данные, если только этот столбец не требуется для инструмента загрузки данных, базы данных или правил конфигурации сайта. На самом деле рекомендуется опускать ненужные столбцы, чтобы упростить структуру файла данных и снизить вероятность появления ошибок в ненужном столбце. Нельзя пропустить поля, необходимые для инструмента «Загрузить данные», но можно опустить поля, необходимые для базы данных, при условии, что значение по умолчанию подходит для всех записей, которые вы добавляете или редактируете. Если значение по умолчанию не подходит ни для одной из записей в вашем файле данных, необходимо включить этот столбец и указать соответствующие значения для этих записей. Поля назначения в базе данных хранят различные версии значений, представленных на веб-страницах. Например, пользовательская цель «Представитель компании» хранится в базе данных как «company_rep». Значения сопоставляются друг с другом и преобразуются по мере загрузки и выгрузки данных из базы данных. Возможно, будет проще использовать значение базы данных, которое можно увидеть, при загрузке файла данных CSV по ссылкам в верхней части файла данных для загрузки.
Как преобразовать файл Excel в CSV
Если требуется экспортировать файл Excel в какое-либо другое приложение, например, в адресную книгу Outlook или в базу данных Access, предварительно преобразуйте лист Excel в файл CSV, а затем импортируйте файл .csv в другое приложение. Ниже дано пошаговое руководство, как экспортировать рабочую книгу Excel в формат CSV при помощи инструмента Excel – «Сохранить как».
- В рабочей книге Excel откройте вкладку Файл (File) и нажмите Сохранить как (Save as). Кроме этого, диалоговое окно Сохранение документа (Save as) можно открыть, нажав клавишу F12.
- В поле Тип файла (Save as type) выберите CSV (разделители – запятые) (CSV (Comma delimited)).Кроме CSV (разделители – запятые), доступны несколько других вариантов формата CSV:
- CSV (разделители – запятые) (CSV (Comma delimited)). Этот формат хранит данные Excel, как текстовый файл с разделителями запятыми, и может быть использован в другом приложении Windows и в другой версии операционной системы Windows.
- CSV (Macintosh). Этот формат сохраняет книгу Excel, как файл с разделителями запятыми для использования в операционной системе Mac.
- CSV (MS-DOS). Сохраняет книгу Excel, как файл с разделителями запятыми для использования в операционной системе MS-DOS.
- Текст Юникод (Unicode Text (*txt)). Этот стандарт поддерживается почти во всех существующих операционных системах, в том числе в Windows, Macintosh, Linux и Solaris Unix. Он поддерживает символы почти всех современных и даже некоторых древних языков. Поэтому, если книга Excel содержит данные на иностранных языках, то рекомендую сначала сохранить её в формате Текст Юникод (Unicode Text (*txt)), а затем преобразовать в CSV, как описано далее в разделе .
Замечание: Все упомянутые форматы сохраняют только активный лист Excel.
- Выберите папку для сохранения файла в формате CSV и нажмите Сохранить (Save).После нажатия Сохранить (Save) появятся два диалоговых окна. Не переживайте, эти сообщения не говорят об ошибке, так и должно быть.
- Первое диалоговое окно напоминает о том, что В файле выбранного типа может быть сохранён только текущий лист (The selected file type does not support workbooks that contain multiple sheets). Чтобы сохранить только текущий лист, достаточно нажать ОК.Если нужно сохранить все листы книги, то нажмите Отмена (Cancel) и сохраните все листы книги по-отдельности с соответствующими именами файлов, или можете выбрать для сохранения другой тип файла, поддерживающий несколько страниц.
- После нажатия ОК в первом диалоговом окне, появится второе, предупреждающее о том, что некоторые возможности станут недоступны, так как не поддерживаются форматом CSV. Так и должно быть, поэтому просто жмите Да (Yes).
Вот так рабочий лист Excel можно сохранить как файл CSV. Быстро и просто, и вряд ли тут могут возникнуть какие-либо трудности.
Чтение с помощью Pandas
Pandas определяется как библиотека с открытым исходным кодом, которая построена на основе библиотеки NumPy. Он обеспечивает быстрый анализ, очистку данных и подготовку данных для пользователя.
Чтение файла csv в pandas DataFrame выполняется быстро и просто. Нам не нужно писать достаточно строк кода, чтобы открывать, анализировать и читать файл csv в pandas, и он хранит данные в DataFrame.
Здесь мы берем для чтения немного более сложный файл под названием hrdata.csv, который содержит данные сотрудников компании.
Name,Hire Date,Salary,Leaves Remaining John Idle,08/15/14,50000.00,10 Smith Gilliam,04/07/15,65000.00,8 Parker Chapman,02/21/14,45000.00,10 Jones Palin,10/14/13,70000.00,3 Terry Gilliam,07/22/14,48000.00,7 Michael Palin,06/28/13,66000.00,8
Пример:
import pandas
df = pandas.read_csv('hrdata.csv')
print(df)
В приведенном выше коде трех строк достаточно для чтения файла, и только одна из них выполняет фактическую работу, то есть pandas.read_csv()
Выход:
Name Hire Date Salary Leaves Remaining 0 John Idle 03/15/14 50000.0 10 1 Smith Gilliam 06/01/15 65000.0 8 2 Parker Chapman 05/12/14 45000.0 10 3 Jones Palin 11/01/13 70000.0 3 4 Terry Gilliam 08/12/14 48000.0 7 5 Michael Palin 05/23/13 66000.0 8
Examples¶
The simplest example of reading a CSV file:
import csv
with open('some.csv', newline='') as f
reader = csv.reader(f)
for row in reader
print(row)
Reading a file with an alternate format:
import csv
with open('passwd', newline='') as f
reader = csv.reader(f, delimiter=':', quoting=csv.QUOTE_NONE)
for row in reader
print(row)
The corresponding simplest possible writing example is:
import csv
with open('some.csv', 'w', newline='') as f
writer = csv.writer(f)
writer.writerows(someiterable)
Since is used to open a CSV file for reading, the file
will by default be decoded into unicode using the system default
encoding (see ). To decode a file
using a different encoding, use the argument of open:
import csv
with open('some.csv', newline='', encoding='utf-8') as f
reader = csv.reader(f)
for row in reader
print(row)
The same applies to writing in something other than the system default
encoding: specify the encoding argument when opening the output file.
Registering a new dialect:
import csv
csv.register_dialect('unixpwd', delimiter=':', quoting=csv.QUOTE_NONE)
with open('passwd', newline='') as f
reader = csv.reader(f, 'unixpwd')
A slightly more advanced use of the reader — catching and reporting errors:
import csv, sys
filename = 'some.csv'
with open(filename, newline='') as f
reader = csv.reader(f)
try
for row in reader
print(row)
except csv.Error as e
sys.exit('file {}, line {}{}'.format(filename, reader.line_num, e))
And while the module doesn’t directly support parsing strings, it can easily be
done:
import csv
for row in csv.reader():
print(row)
Footnotes
- 1(,)
-
If is not specified, newlines embedded inside quoted fields
will not be interpreted correctly, and on platforms that use linendings
on write an extra will be added. It should always be safe to specify
, since the csv module does its own
() newline handling.
Файлы CSV
Последнее обновление: 29.04.2017
Одним из распространенных файловых форматов, которые хранят в удобном виде информацию, является формат csv.
Каждая строка в файле csv представляет отдельную запись или строку, которая состоит из отдельных столбцов, разделенных запятыми. Собственно поэтому
формат и называется Comma Separated Values. Но хотя формат csv — это формат текстовых файлов, Python для упрощения работы с ним
предоставляет специальный встроенный модуль csv.
Рассмотрим работу модуля на примере:
import csv
FILENAME = "users.csv"
users = ,
,
]
with open(FILENAME, "w", newline="") as file:
writer = csv.writer(file)
writer.writerows(users)
with open(FILENAME, "a", newline="") as file:
user =
writer = csv.writer(file)
writer.writerow(user)
В файл записывается двухмерный список — фактически таблица, где каждая строка представляет одного пользователя. А каждый пользователь
содержит два поля — имя и возраст. То есть фактически таблица из трех строк и двух столбцов.
При открытии файла на запись в качестве третьего параметра указывается значение — пустая строка позволяет корректно считывать
строки из файла вне зависимости от операционной системы.
Для записи нам надо получить объект writer, который возвращается функцией . В эту функцию передается открытый файл.
А собственно запись производится с помощью метода Этот метод принимает набор строк. В нашем случае это двухмерный список.
Если необходимо добавить одну запись, которая представляет собой одномерный список, например, , то в этом случае можно вызвать метод
writer.writerow(user)
В итоге после выполнения скрипта в той же папке окажется файл users.csv, который будет иметь следующее содержимое:
Tom,28 Alice,23 Bob,34 Sam,31
Для чтения из файла нам наоборот нужно создать объект reader:
import csv
FILENAME = "users.csv"
with open(FILENAME, "r", newline="") as file:
reader = csv.reader(file)
for row in reader:
print(row, " - ", row)
При получении объекта reader мы можем в цикле перебрать все его строки:
Tom - 28 Alice - 23 Bob - 34 Sam - 31
Работа со словарями
В примере выше каждая запись или строка представляла собой отдельный список, например, . Но кроме того, модуль csv имеет
специальные дополнительные возможности для работы со словарями. В частности, функция csv.DictWriter() возвращает объект writer,
который позволяет записывать в файл. А функция csv.DictReader() возвращает объект reader для чтения из файла. Например:
import csv
FILENAME = "users.csv"
users =
with open(FILENAME, "w", newline="") as file:
columns =
writer = csv.DictWriter(file, fieldnames=columns)
writer.writeheader()
# запись нескольких строк
writer.writerows(users)
user = {"name" : "Sam", "age": 41}
# запись одной строки
writer.writerow(user)
with open(FILENAME, "r", newline="") as file:
reader = csv.DictReader(file)
for row in reader:
print(row, "-", row)
Запись строк также производится с помощью методов и . Но теперь каждая строка представляет собой отдельный словарь,
и кроме того, производится запись и заголовков столбцов с помощью метода writeheader(), а в метод csv.DictWriter в качестве второго параметра
передается набор столбцов.
При чтении строк, используя названия столбцов, мы можем обратиться к отдельным значениям внутри строки: .
НазадВперед
Проверяем кодировку CSV файла
Для того чтобы успешно открыть CSV файл в Excel желательно предварительно проверить его кодировку, и, если это необходимо, выполнить преобразование в ANSI. Дело в том, что при открытии CSV файлов Excel по умолчанию использует кодировку ANSI. Поэтому, если ваш файл закодирован с использованием UTF-8 или какой-то другой кодировки, то при его открытии будут возникать проблемы с отображением кириллицы.
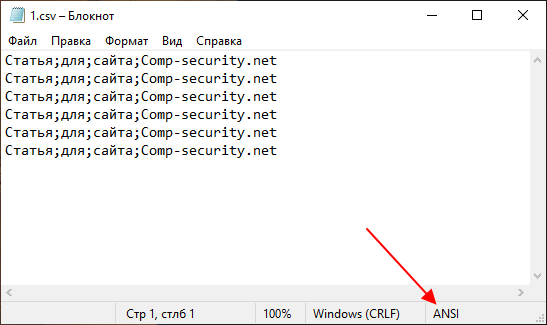
Если ваш CSV файл небольшого размера, то для проверки кодировки и преобразования можно использовать программу «Блокнот», которая идет в комплекте с Windows
Для этого откройте CSV файл в «Блокноте» и обратите внимание на нижний правый угол окна, там будет указана кодировка. Если в качестве кодировки используется «ANSI», то все нормально, можно переходить к открытию CSV файла в Excel
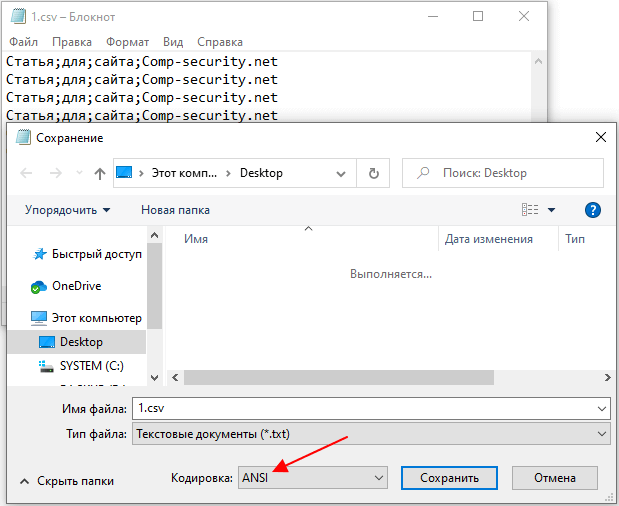
Если же используется другая кодировка (например, UTF-8), то файл нужно сначала преобразовать в ANSI.
воспользуйтесь меню «Файл – Сохранить как». После этого в окне сохранения файла нужно указать кодировку «ANSI» и сохранить файл.
Как структурированы csv файлы
Шаблоны CSV или файлы данных можно загрузить по ссылкам в верхней части инструмента «Загрузить данные». Первая строка шаблона или файла данных содержит заголовки столбцов. Каждая последующая строка соответствует записи в базе данных. Когда загружается шаблон CSV, он содержит только заголовки столбцов. Поскольку шаблоны используются для добавления новых записей, новые строки будут добавляться для каждой записи.
Когда документ данных CSV загружается, первая строка содержит заголовок столбца, а последующие строки содержат записи данных, которые уже существуют в базе данных. Записи в этих строках можно редактировать или удалять.
В документе CSV каждая строка содержит упорядоченную последовательность заголовков столбцов или значений, разделенных запятыми. Запятые используются для сохранения файловой структуры. Каждая запятая в первой строке (которая содержит заголовки столбцов) разделяет заголовок столбца и место в упорядоченной последовательности столбцов.
Запятые в последующих строках также поддерживают последовательность упорядоченных столбцов, поэтому первое значение в каждой последующей строке представляет значение в первом столбце, второе значение в каждой последующей строке представляет значение во втором столбце и так далее. В отличие от стандартной пунктуации предложений, после запятой не ставится пробел.
Большинство значений заключено в двойные кавычки. Исключением является односимвольное значение, например 1 или 0 (ноль). Заключение значения в двойные кавычки позволяет использовать в поле сложные значения, например, содержащие запятые, без нарушения структуры документа. Например, поле, содержащее ряд элементов, например избранные цвета, может иметь такое значение:
“красный, зеленый и синий”
Вы не будете знать об этих цитатах при просмотре файла данных в приложении для работы с электронными таблицами, но они появляются, когда file просматривается в текстовом редакторе.
Заключение
CSV-файлы — пережиток прошлого, но, несмотря на наличие более удобных и эффективных форматов XML и JSON, по-прежнему широко используются как формат для обмена данными. CSV-файлам недостает общепринятой спецификации или стандарта, и, хотя у них много общих черт, вы не можете быть уверены, что ожидаемые символы окажутся в конкретном файле. Это делает разбор CSV-файла нетривиальным упражнением.
Будь на то выбор, большинство разработчиков, по-видимому, исключило бы CSV-файлы из своих решений. Однако их широкая распространенность в устаревших корпоративных и правительственных наборах данных препятствует этому в большинстве случаев.
Если в двух словах, существует потребность в средстве разбора CSV для приложений Universal Windows Platform (UWP), и оно должно быть гибким и надежным. Заодно я продемонстрировал здесь применение на практике встраивание зависимостей, которое и обеспечивает гибкость. Хотя эта статья и приведенный в ней код ориентированы на UWP-приложения, сама концепция и код применимы к другим платформам, способным работать с C#, например к Microsoft Azure или настольным Windows-приложениям.
Фрэнк Ла-Вине (Frank La Vigne) —идеолог технологий в группе Microsoft Technology and Civic Engagement, где он помогает пользователям применять технологии и формировать соответствующие сообщества. Регулярно ведет блог на FranksWorld.com и имеет канал на YouTube под названием «Frank’s World TV» (youtube.com/FranksWorldTV).
Выражаю благодарность за рецензирование статьи эксперту Рэчел Аппель (Rachel Appel).